监控
最近更新时间:2024.05.15 15:24:08
首次发布时间:2023.04.23 14:32:55
机器学习平台为常用的负载都提供了监控看板并预置了大量的监控指标,但仍然有可能无法满足部分用户的定制化需求,最为常见的有基于某些基础指标进行聚合得到新的指标。为解决这类问题,机器学习平台支持用户将监控数据归档至自身火山引擎账号下的托管 Prometheus 服务(VMP) ,归档后的数据用户能够自由查询及灵活使用。
- VMP。
当前用户拥有
MLPlatformAdminAccess的 IAM 策略(配置策略的方法详见权限管理)。当前账号下拥有 >=1 个 VMP 工作区。
- 如果该账号下未创建过工作时,可能联系具备相关权限如
VMPFullAccessIAM 策略的用户前往 VMP 的控制台页面创建。
- 如果该账号下未创建过工作时,可能联系具备相关权限如
前往机器学习平台的【全局配置】-【监控】模块,单击【授权】进入配置页面。
启动监控归档的功能并将适当的 VMP 工作区配置为归档位置。
提交表单后新创建的负载的监控数据将推送至对应的 VMP 工作区,用户即可实现数据的自由处理。
注意事项
- 开启归档之前创建的自定义任务、在线服务的监控数据不会推送至 VMP,但是开发机关机再开机后可推送。
- 修改归档位置后,旧的自定义任务、在线服务只会推送到旧的归档位置,开发机关机再开机后可推送到新的归档位置。
监控数据归档到用户的 VMP 后可以完整地查看各项指标,此外也可以利用这部分指标在 VMP 上配置告警。详细的指标和 label 列表详见下文中的指标及 label 说明。
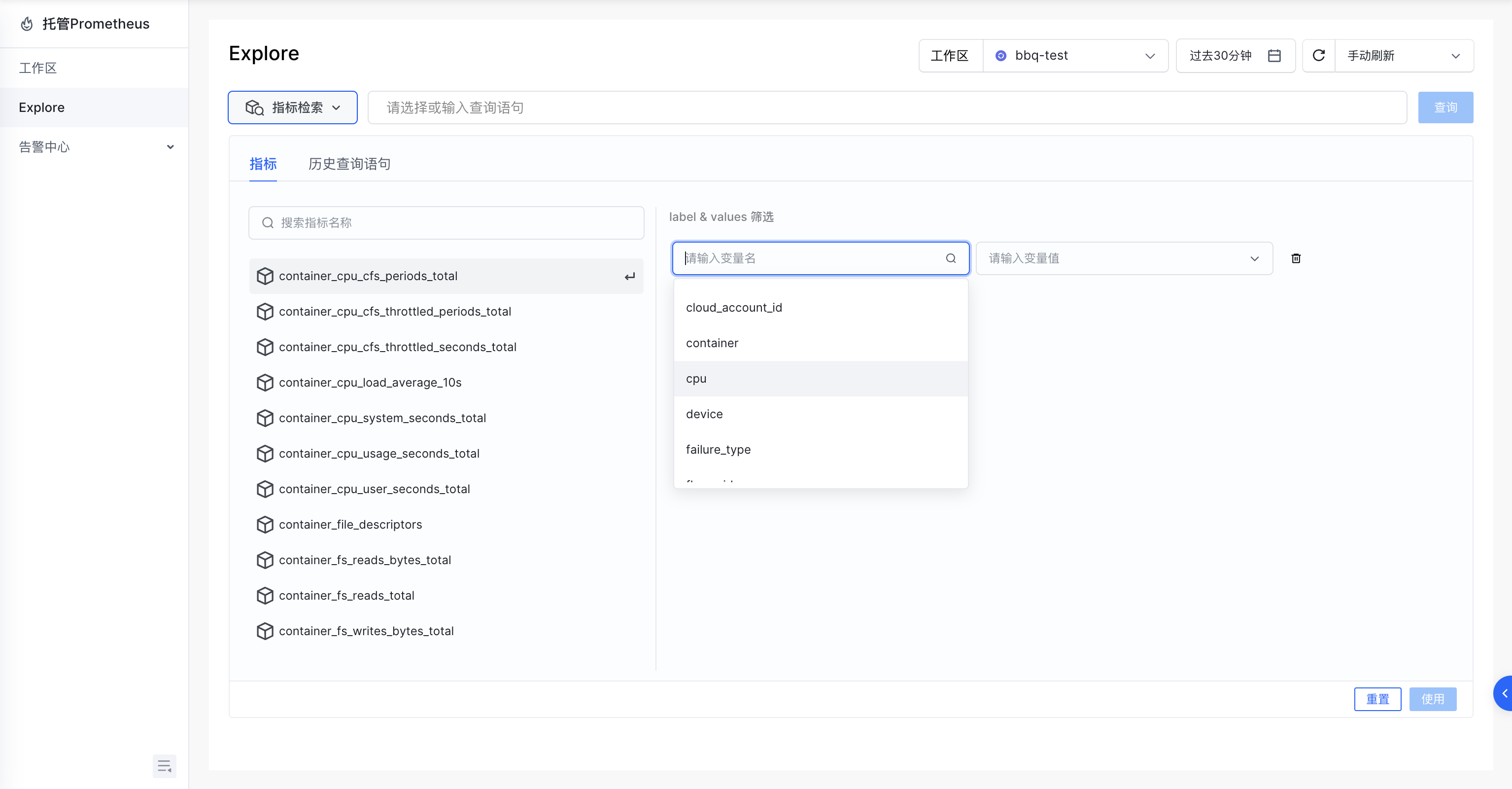
VMP Explore 指标检索
前往 VMP 的【Explore】模块,选择用作监控数据归档的工作区。
在查询框内输入指标名称或 PromQL 查询语句。
通过 label 和 values 还能做更细粒度的筛选。
自建 Grafana 监控看板
Grafana 是一个跨平台的开源度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示。您可以通过火山引擎为您提供的镜像来部署 Grafana,也可以使用开源的镜像部署。部署 Grafana 的方法如下:
方法 1:在火山引擎容器服务 VKE 中部署 Grafana,详见VMP - 部署 Grafana。
方法 2:在火山引擎云服务器 ECS 中部署 Grafana。
前往 ECS 创建实例并在实例中安装 Grafana。
为 ECS 绑定公网 IP,并设置安全组规则:入方向规则中,允许 Grafana 端口(默认为3000)。
在浏览器访问
http://<公网IP>:<``Grafana 端口``>,初始用户名和密码都为admin。在 Grafana 设置中新增数据源,选择 Prometheus,填入 VMP 的 Basic Auth、Query URL(上述信息均可从 VMP 的工作区详情页面获得)。
通过 VMP 配置告警
因为所有监控数据已经推送到用户的 VMP 下,用户便能够通过编写 PromQL 查询语句灵活地配置告警规则,当机器学习平台的工作负载的监控指标出现异常时可以及时地发送告警消息给对应的告警联系群组。具体操作步骤详见创建告警规则。
PromQL检索示例
- CPU 使用量。
irate(container_cpu_usage_seconds_total{name!=""}[5m])
- CPU 使用率。
irate(container_cpu_usage_seconds_total{name!=""}[5m])/on (pod,name) (container_spec_cpu_quota/1000/100)*100_spec_cpu_quota/1000/100)*100
- 显存利用率。
avg by(gpu, pod)(DCGM_FI_DEV_FB_USED{pod="%s"} / (DCGM_FI_DEV_FB_FREE{pod="%s"} + DCGM_FI_DEV_FB_USED{pod="%s"}) * 100)
- 查看每个自定义任务的平均 GPU 利用率(因为自定义任务中一个任务会有多个 pod,需要按任务 id 聚合一下)。
avg (DCGM_FI_DEV_GPU_UTIL * ON(pod) group_left(mlp_customtask) mlp_customtask_instance_info) by (mlp_customtask)
- 实现 10 天内某个队列(q-20211224114108-78qvl)各个自定义任务的平均利用率(各任务生命周期内的平均利用率)。
avg_over_time( (avg ( DCGM_FI_DEV_GPU_UTIL * ON(pod) group_left(mlp_customtask) mlp_customtask_instance_info{mlp_resource_queue="q-20211224114108-78qvl"}) by (mlp_customtask)) [10d:30s])
- 某个任务(t-20230519123538-vr2nl)10 天内的 GPU 使用时间。
- 该任务使用了多少张 GPU 则监控图表中展示多少条数据曲线。
count_over_time(DCGM_FI_DEV_GPU_UTIL AND ON(pod) mlp_customtask_instance_info{mlp_customtask="t-20230519123538-vr2nl"} [10d:1m])
- 按照任务的维度统计过去 5 天内每种 GPU 型号的总使用卡时。
- 查询语句解析:
count_over_time():计算指定时间范围内的样本数量。在该示例中用于计算过去 1 天每分钟内的样本数量。DCGM_FI_DEV_GPU_UTIL: 该示例中选择了DCGM_FI_DEV_GPU_UTIL指标用于计算使用时间* ON(pod) group_left(mlp_customtask) mlp_customtask_instance_info: 该示例中要筛选自定义任务,需要将DCGM指标和自定义任务实例指标按照相同pod进行匹配。由于单个pod可能有多张卡, 需要使用group_left操作进行多对一匹配, 并将自定义任务IDmlp_customtask传递给最终结果。详细的匹配规则请参阅PromQL官方文档。sum by (mlp_customtask, modelName): 对于相同mlp_customtask和modelName标签值的数据点,将它们的计数值相加得到一个总数。- 其中
modelName为 DCGM 自带的标签,指 GPU 型号。
- 其中
- 查询语句解析:
sum by (mlp_customtask, modelName) (count_over_time((DCGM_FI_DEV_GPU_UTIL * ON(pod) group_left(mlp_customtask) mlp_customtask_instance_info)[5d:1m]))
DCGM常见指标
指标描述
| 指标 | 类型 | 单位 | 含义 |
|---|---|---|---|
| DCGM_FI_DEV_SM_CLOCK | Gauge | MHz | SM时钟频率 |
| DCGM_FI_DEV_MEM_CLOCK | Gauge | MHz | SM内存时钟频率 |
| DCGM_FI_DEV_POWER_USAGE | Gauge | W | 功率 |
| DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION | Counter | mJ | 能量消耗 |
| DCGM_FI_DEV_PCIE_REPLAY_COUNTER | Counter | 次 | PCIe replay 次数 |
| DCGM_FI_DEV_GPU_UTIL | Gauge | % (1-100) | 单位时间内至少一个核函数处于Active的时间的百分比 |
| DCGM_FI_DEV_MEM_COPY_UTIL | Gauge | % (1-100) | 内存带宽利用率 |
| DCGM_FI_DEV_ENC_UTIL | Gauge | % (1-100) | 编码器利用率 |
| DCGM_FI_DEV_DEC_UTIL | Gauge | % (1-100) | 解码器利用率 |
| DCGM_FI_DEV_XID_ERRORS | Gauge | - | 上一次发生的 XID 错误的错误码 |
| DCGM_FI_DEV_POWER_VIOLATION | Counter | μs | 因功率上限而导致的违规的累积持续时间 |
| DCGM_FI_DEV_THERMAL_VIOLATION | Counter | μs | 因热限制导致的违规的累积持续时间 |
| DCGM_FI_DEV_SYNC_BOOST_VIOLATION | Counter | μs | 因同步提升限制而导致的违规的累积持续时间 |
| DCGM_FI_DEV_BOARD_LIMIT_VIOLATION | Counter | μs | 因电路板限制而导致的违规的累积持续时间 |
| DCGM_FI_DEV_LOW_UTIL_VIOLATION | Counter | μs | 因低利用率限制导致的违规的累积持续时间 |
| DCGM_FI_DEV_RELIABILITY_VIOLATION | Counter | μs | 因电路板可靠性限制导致违规的累积持续时间 |
| DCGM_FI_DEV_FB_FREE | Gauge | MB | 未使用的BAR1 |
| DCGM_FI_DEV_FB_USED | Gauge | MB | 已使用的BAR1 |
| DCGM_FI_DEV_RETIRED_SBE | Counter | 个 | 因单bit错误而停用的 page |
| DCGM_FI_DEV_RETIRED_DBE | Counter | 个 | 因双bit错误而停用的 page |
| DCGM_FI_PROF_GR_ENGINE_ACTIVE | Gauge | % (1-100) | 在一个时间间隔内,Graphics或Compute引擎处于Active的时间占比 |
| DCGM_FI_PROF_SM_ACTIVE | Gauge | 占比(0-1) | 在一个时间间隔内,至少一个线程束在一个SM 上处于Active的时间占比。统计的是所有 SM 的均值 |
| DCGM_FI_PROF_SM_OCCUPANCY | Gauge | % (1-100) | 在一个时间间隔内,驻留在SM上的线程束与该SM最大可驻留线程束的比例。统计的是所有 SM 的均值 |
| DCGM_FI_PROF_PIPE_TENSOR_ACTIVE | Gauge | % (1-100) | 单位时间内 Tensor Pipes 平均处于Active 状态的周期分数 |
| DCGM_FI_PROF_DRAM_ACTIVE | Gauge | % (1-100) | 内存拷贝活跃周期分数(一个周期内有一次 DRAM 指令则该周期为 100%) |
| DCGM_FI_PROF_PIPE_FP64_ACTIVE | Gauge | % (1-100) | 单位时间内 F64 Pipes 平均处于Active 状态的周期分数 |
| DCGM_FI_PROF_PIPE_FP32_ACTIVE | Gauge | % (1-100) | 单位时间内 F32 Pipes 平均处于Active 状态的周期分数 |
| DCGM_FI_PROF_PIPE_FP16_ACTIVE | Gauge | % (1-100) | 单位时间内 F16 Pipes 平均处于Active 状态的周期分数 |
| DCGM_FI_PROF_PCIE_TX_BYTES | Counter | B/s | 通过 PCIe 总线传输的数据流量 |
| DCGM_FI_PROF_PCIE_RX_BYTES | Counter | B/s | 通过 PCIe 总线接收的数据流量 |
| DCGM_FI_PROF_NVLINK_RX_BYTES | Counter | B/s | 通过 NVLink 传输的数据流量 |
| DCGM_FI_PROF_NVLINK_TX_BYTES | Counter | B/s | 通过 NVLink 接收的数据流量 |
标签描述
公共标签
| 标签名 | 示例值 | 含义 |
|---|---|---|
| Hostname | dcgm-exporter-abcde | 指标源dcgm-exporter实例名称 |
| UUID | GPU-000000000-0000-0000-0000-000000000000 | GPU UUID标识符 |
| container | mljob | 使用GPU的容器名称 |
| device | nvidia1 | GPU设备名称 |
| gpu | 1 | GPU编号 |
| instance | t-20240101120000-abcde-worker-0 | 使用GPU的实例id |
| modelName | NVIDIA A10 | GPU型号 |
| namespace | mlplatform-customtask | 实例所在Kubernetes命名空间 |
cAdvisor常见指标
指标描述
| 分类 | 指标 | 类型 | 单位 | 指标含义 |
|---|---|---|---|---|
| CPU | container_cpu_load_average_10s | gauge | - | 过去 10 秒容器 CPU 的平均负载 |
| container_cpu_usage_seconds_total | counter | s | 容器 CPU 累计使用量 | |
| container_cpu_system_seconds_total | counter | s | System CPU 累计占用时间 | |
| container_cpu_user_seconds_total | counter | s | User CPU 累计占用时间 | |
| 内存 | container_memory_max_usage_bytes | gauge | Byte | 容器的最大内存使用量 |
| container_memory_usage_bytes | gauge | Byte | 容器当前的内存使用量,包括缓存等可释放的内存 | |
| container_memory_working_set_bytes | gauge | Byte | 容器当前的内存使用量 | |
| container_spec_memory_limit_bytes | gauge | Byte | 容器的内存使用量限制 | |
| machine_memory_bytes | gauge | Byte | 当前主机的内存总量 |
标签描述
公共标签
| 标签名 | 示例值 | 含义 |
|---|---|---|
| id | /kubepods/burstable/pod-id/container-name | 容器的全局id标识 |
| image | python:3.10 | 容器镜像的名称和版本标签 |
| name | container-name | 容器名称 |
| namespace | mlplatform-service | 所属命名空间名称 |
| pod | s-20240101120000-abcde-abcde | 容器所属 Pod id |
| job | kubernetes-cadvisor | 固定的采集来源名称 |
资源组指标
指标描述
| 指标 | 类型 | 单位 | 含义 |
|---|---|---|---|
| mlp_resourcegroup_info | Gauge | - | ResourceGroup 的元数据,取值永远为 1 |
| mlp_resourcegroup_created_timestamp_seconds | Gauge | s | 创建时间(UNIX 时间戳) |
| mlp_resourcegroup_resource_capacity | Gauge | - | ResourceGroup 资源的 ResourceCapability 字段,取值为具体 resource 的值,换算为 unit 中标注的单位 |
| mlp_resourcegroup_flavor_capacity | Gauge | 个 | ResourceGroup 资源的 FlavorCapability 字段,描述资源组各规格的实例数量上限 |
| mlp_resourcegroup_flavor_allocated | Gauge | 个 | ResourceGroup 资源的 FlavorAllocated 字段,描述资源组各规格的已分配实例数量 |
| mlp_resourcegroup_volume_capacity | Gauge | GiB | ResourceGroup 资源的 VolumeCapability 字段,描述资源组各规格的云盘容量上限 |
| mlp_resourcegroup_volume_allocated | Gauge | GiB | ResourceGroup 资源的 VolumeAllocated 字段,描述资源组各规格的已分配云盘容量 |
| mlp_resourcegroup_expired_timestamp_seconds | Gauge | s | ResourceGroup 资源的 ExpiredTime 字段,取值为字段值转换为 Unix 时间戳 |
| mlp_resourcegroup_state | Gauge | - | ResourceGroup 资源的 State 字段,取值逻辑是,如果当前状态是 state label 对应值,则取 1,否则取 0 |
标签描述
公共标签
| 标签名 | 示例值 | 标签含义 |
|---|---|---|
| mlp_resource_group | r-20240101120000-abcde | 资源组id |
专有标签
| 指标 | 标签名 | 示例值 | 标签含义 |
|---|---|---|---|
| mlp_resourcegroup_info | charge_type | PrePaid | 资源组计费方式 |
| mlp_resourcegroup_resource_capacity | resource | GPU | 资源类型,可选值:VCPU,Memory,RDMA_ENI,GPU_Memory,GPU |
| gpu_type | NVIDIA A10 | 具体 GPU 型号(非 GPU 资源取空值) | |
| unit | core | 计量单位,可选值:core,GiB,count | |
| mlp_resourcegroup_flavor_capacity | flavor | ml.g1ie.large | 实例规格 |
| availability_zone | cn-beijing-a | 所在可用区 | |
| mlp_resourcegroup_flavor_allocated | flavor | ml.g1ie.large | 实例规格 |
| availability_zone | cn-beijing-a | 所在可用区 | |
| mlp_resourcegroup_volume_capacity | flavor | ml.essd.pl1 | 云盘规格 |
| availability_zone | cn-beijing-a | 所在可用区 | |
| mlp_resourcegroup_volume_allocated | flavor | ml.essd.pl1 | 云盘规格 |
| availability_zone | cn-beijing-a | 所在可用区 | |
| mlp_resourcegroup_state | state | Running | 资源组 State 字段的枚举值 |
队列指标
指标描述
| 指标 | 类型 | 单位 | 含义 |
|---|---|---|---|
| mlp_resourcequeue_info | Gauge | - | 队列的元数据。取值永远为 1。 |
| mlp_resourcequeue_created_timestamp_seconds | Gauge | s | 创建时间(UNIX 时间戳) |
| mlp_resourcequeue_quota_capacity | Gauge | - | ResourceQueue 资源的 QuotaCapability 字段,取值为具体 resource 的值,换算为 unit 中标注的单位 |
| mlp_resourcequeue_quota_allocated | Gauge | - | ResourceQueue 资源的 QuotaAllocated 字段,取值为具体 resource 的值,换算为 unit 中标注的单位 |
| mlp_resourcequeue_flavor_resources | Gauge | 个 | ResourceQueue 资源的 FlavorResources 字段,描述队列各规格的实例数量 |
| mlp_resourcequeue_volume_capacity | Gauge | GiB | ResourceQueue 资源的 VolumeCapability 字段,描述队列各规格的云盘容量上限 |
| mlp_resourcequeue_volume_allocated | Gauge | GiB | ResourceQueue 资源的 VolumeAllocated 字段,描述队列各规格的已分配云盘容量 |
| mlp_resourcequeue_state | Gauge | - | ResourceQueue 资源的 State 字段,取值逻辑是,如果当前状态是 state label 对应值,则取 1,否则取 0 |
标签描述
公共标签
| 标签名 | 示例值 | 标签含义 |
|---|---|---|
| mlp_resource_queue | q-20240101120000-abcde | 队列id |
专有标签
| 指标 | 标签名 | 示例值 | 标签含义 |
|---|---|---|---|
| mlp_resourcequeue_info | mlp_resource_group | r-20240101120000-abcde | 队列所属资源组的id |
| availability_zone | cn-beijing-a | 所在可用区 | |
| charge_type | PrePaid | 资源组计费方式 | |
| mlp_resourcequeue_quota_capacity | resource | GPU | 资源类型,可选值:VCPU,Memory,RDMA_ENI,GPU_Memory,GPU |
| gpu_type | NVIDIA A10 | 具体 GPU 型号(非 GPU 资源取空值) | |
| unit | core | 计量单位,可选值:core,GiB,count | |
| mlp_resourcequeue_quota_allocated | resource | GPU | 资源类型,可选值:VCPU,Memory,RDMA_ENI,GPU_Memory,GPU |
| gpu_type | NVIDIA A10 | 具体 GPU 型号(非 GPU 资源取空值) | |
| unit | core | 计量单位,可选值:core,GiB,count | |
| mlp_resourcequeue_flavor_resources | flavor | ml.g1ie.large | 实例规格 |
| mlp_resourcequeue_volume_capacity | flavor | ml.essd.pl1 | 云盘规格 |
| mlp_resourcequeue_volume_allocated | flavor | ml.essd.pl1 | 云盘规格 |
| mlp_resourcequeue_state | state | Running | 队列 State 字段的枚举值 |
工作负载指标
指标描述
| 分类 | 指标 | 类型 | 单位 | 指标含义 |
|---|---|---|---|---|
| 自定义任务 | mlp_customtask_info | Gauge | - | 自定义任务元数据。取值永远为 1。 |
| mlp_customtask_instance_info | Gauge | - | 自定义任务实例元数据。取值永远为 1。 | |
| 在线服务 | mlp_service_info | Gauge | - | 在线服务元数据。取值永远为 1。 |
| mlp_deployment_info | Gauge | - | 在线服务部署元数据。取值永远为 1。 | |
| mlp_deployment_instance_info | Gauge | - | 在线服务实例元数据。取值永远为 1。 | |
| 开发机 | mlp_devinstance_info | Gauge | - | 开发机元数据。取值永远为 1。 |
| 实例 | mlp_instance_pod_status_phase | Gauge | - | 负载实例的Kubernetes Pod Phase状态 |
| mlp_instance_pod_status_ready | Gauge | - | 负载实例的Kubernetes Pod Ready状态 | |
| mlp_instance_created_timestamp_seconds | Gauge | s | 实例的创建时间(UNIX 时间戳) | |
| mlp_instance_resource_requests | Gauge | - | 实例占用的逻辑资源 |
标签描述
| 分类 | 指标 | 标签名 | 标签含义 |
|---|---|---|---|
| 自定义任务 | mlp_customtask_info | mlp_customtask | 资源 ID |
| mlp_pipeline | 所属流水线 ID | ||
| mlp_resource_group | 任务所属资源组 ID | ||
| mlp_resource_queue | 任务所属队列 ID | ||
| mlp_customtask_instance_info | mlp_customtask | 实例所属任务 ID | |
| namespace | 实例所属 K8 namespace | ||
| pod | 实例对应的 K8 Pod | ||
| role | 实例角色 | ||
| role_index | 实例序号(按角色) | ||
| flavor | 实例规格,如 ml.g1ie.large | ||
| mlp_pipeline | 所属流水线 ID | ||
| mlp_resource_group | 任务所属资源组 ID | ||
| mlp_resource_queue | 任务所属队列 ID | ||
| availability_zone | 所在可用区 | ||
| 在线服务 | mlp_service_info | mlp_service | 资源 ID |
| type | 服务类型,大写驼峰格式,如 General 或 Credible | ||
| mlp_deployment_info | mlp_deployment | 资源 ID | |
| mlp_service | 部署所属的服务的 ID | ||
| type | 部署类型,大写驼峰格式,如 Stable,Canary,和 Debug | ||
| mlp_resource_group | 所属资源组 ID | ||
| mlp_resource_queue | 所属队列 ID | ||
| availability_zone | 所在可用区 | ||
| mlp_deployment_instance_info | mlp_deployment | 实例所属的部署的 ID | |
| mlp_service | 实例所属的服务的 ID | ||
| mlp_service_instance | 实例 ID | ||
| role | 实例角色 | ||
| role_index | 实例序号(按角色) | ||
| namespace | 实例所属 K8 namespace | ||
| pod | 实例对应的 K8 Pod | ||
| flavor | 实例规格,如 ml.g1ie.large | ||
| mlp_resource_group | 所属资源组 ID | ||
| mlp_resource_queue | 所属队列 ID | ||
| availability_zone | 所在可用区 | ||
| 开发机 | mlp_devinstance_info | mlp_devinstance | 开发机 ID |
| namespace | 实例所属 K8 namespace | ||
| pod | 实例对应的 K8 Pod | ||
| flavor | 实例规格,如 ml.g1ie.large | ||
| mlp_resource_group | 所属资源组 ID | ||
| mlp_resource_queue | 所属队列 ID | ||
| availability_zone | 所在可用区 | ||
| 实例 | mlp_instance_pod_status_phase | pod | Pod 名 |
| phase | Pod phase 的枚举值,包含 Failed,Pending,Running,Succeeded,Unknown,当前 phase 的指标值取 1 其他 phase 取 0 | ||
| mlp_instance_pod_status_ready | pod | Pod 名 | |
| ready | Ready condition 的枚举值,包含True/False/Unknown,pod当前ready的状态取1,其他取0 | ||
| mlp_instance_created_timestamp_seconds | pod | Pod 名 | |
| mlp_instance_resource_requests | pod | Pod 名 | |
| resource | 可选值:VCPU,Memory,GPU | ||
| gpu_type | 具体 GPU 型号(非 GPU 资源取空值) | ||
| unit | 计量单位,可选值:core, GiB, count | ||
| mlp_instance_info | pod | Pod 名 | |
| mlp_resource_queue | 实例所属队列ID | ||
| mlp_resource_group | 实例所属资源组ID |