HaMergeTree
最近更新时间:2023.12.20 11:05:26
首次发布时间:2022.12.15 10:08:27
HaMergeTree 是 ByteHouse 自研的引擎,是 ClickHouse 社区的 MergeTree 引擎的高可用版,支持主备数据同步。ByteHouse 默认使用HaMergeTree引擎。
相比起社区的 ReplicatedMergeTree,HaMergeTree 在实现多副本的同时,减少了 ZooKeeper 的依赖,单集群可支持的总数表比社区版更多(1W以上)。
架构与原理
每个分片 的 HaMergeTree 数据会相互同步,保持数据一致,因此查询同一分片任一一副本的 HaMergeTree 得到结果都是一致的。当其中任一节点发生故障时,只要该分片下仍有存活的节点,数据仍然保持可查。节点故障后进行替换,新节点上的数据也会被仍存活的节点的 HaMergeTree 表同步。
若当前集群是单副本模式,也可以创建 HaMergeTree 表,但根据定义,此时分片内只有一个副本,因此不存在数据同步,这张 HaMergeTree 表的表现行为和普通的 MergeTree 表一致。
需要注意的是,不同 Shard 中 HaMergeTree 的数据是不同的。此时需要 Distributed 表汇集不同节点的数据,统一返回。关于 Distributed 表的详情请见见 Distributed。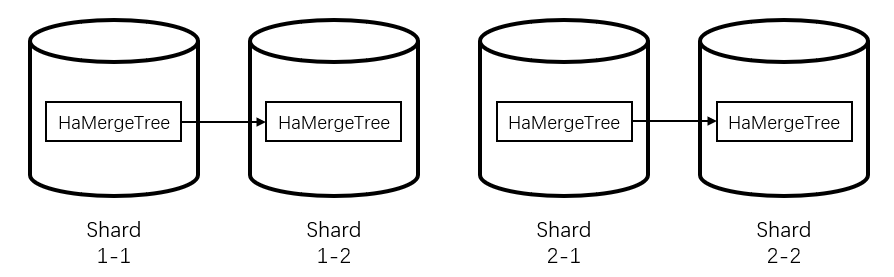
建表
SQL 建表
以下示仅描述了如何建一张 HaMergeTree 表,若你直接使用 SQL 建表,作为最佳实践,你仍需新建一张 Distributed 表,详情请见 Distributed。
CREATE TABLE [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2], ... ) ENGINE = HaMergeTree(shard, replica) -- 默认为 '/clickhouse/bytehouse/库名.表名/{shard}','{replica}' PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash32(UserID)) [PRIMARY KEY expr] [SAMPLE BY expr] [TTL expr] [SETTINGS name=value, ...]
关键参数
- 排序键(ORDER BY):
- ByteHouse 为了提高查询性能, 存储数据时会根据排序索引顺序存储。
- 排序键可以不唯一。但是不能为 Nullable。
- 建议选择 1-3 个经常作为过滤条件的字段作为排序键,使用频率越高,对应顺序越优先。当优先级近似时,选择基数较小的排序索引位于更优先的顺序。
- 分区字段不必为排序索引。
- 主键(PRIMARY KEY):
- 在索引文件(.idx)记录的就是行与主键的对应关系。它默认和排序索引是一致的,通常也不需要额外设置。
- 主键不能包含 Nullable 值。一个数据表只能选择一个主键。
- 抽样字段(SAMPLE BY):
- 默认取第一个主键字段,用于在查询抽样时使用。请参考社区 Sample by 语法。
- 必须是排序索引 / 主键之一。
- 分区字段(PARTITION BY):
- 推荐的类型:时间类型(Date/DateTime),选择时间类型为最佳实践,且建议将 DateTime 类型通过 toDate() 转为 Date 类型作为分区键。
- 如果无需进行分区时,可以不选分区键。
- 分区字段不可以为 Nullable
- TTL:
- 设置数据生命周期,生效粒度为表级别。
- 数据保留时间是以“分区字段”作为基础进行计算,因此对于非时间分区的表将无法设置 TTL,系统将强制修改为永久保留。
Settings
此部分与 社区 MergeTree 引擎 的 Settings 一致。若采用控制面建表已使用默认值,无需进一步配置。
注意
使用 HaMergeTree 时,请将 remote 配置文件中的 internal_replication 设置为 True,否则会查询到2份数据。