配置 SAP Hana 数据源
最近更新时间:2024.05.16 14:18:50
首次发布时间:2023.10.24 10:38:36
SAP HANA 数据源为您提供读取 SAP HANA 数据的数据集成通道能力,实现将读取出来的数据,写入到不同的目标数据源中。
本文为您介绍 DataSail 的 SAP HANA 数据同步的能力支持情况。
1 使用限制
- 当前仅支持离线读 SAP HANA 数据。
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员
2 支持的字段类型
SAP HANA 离线读字段数据类型支持情况如下:
类型分类 | 数据类型 | 备注 |
|---|---|---|
整数类型 | INT、TINYINT、SMALLINT、MEDIUMINT 和 BIGINT | |
字符串类型 | STRING、VARCHAR、NVARCHAR、SHORTTEXT、ALPHANUM | |
浮点类型 | FLOAT、DOUBLE、DECIMAL、AMALLDECIMAL | |
布尔类型 | BOOLEAN | BOOLEAN 别名 BOOL |
日期时间类型 | DATE、TIMESTAMP、TIME、SECONDDATE | unixtime_micros 别名 DATETIME |
二进制类型 | BINTEXT、VARBINARY、NCLOB、CLOB、BLOB、TEXT | |
数组类型 | multi value | 仅支持元素为 string |
其他 | st_point、st_geometry | 会转为 string 处理 |
3 数据同步任务开发
3.1 数据源注册
新建数据源操作详见配置数据源,下面为您介绍用连接串方式配置 Hana 数据源信息:
参数 | 说明 |
|---|---|
基本配置 | |
数据源类型 | Hana |
接入方式 | 连接串 |
数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 |
参数配置 | |
主机名或 IP 地址 | 连接 Hana 数据库的主机名称或者 IP 地址。 |
端口 | 连接主机的端口号。 |
数据库名 | 输入已创建的 Hana 数据库名称。 |
用户名 | 有权限访问数据库的用户名信息。 |
密码 | 输入用户名对应的密码信息。 |
3.2 新建离线任务
Hana 数据源测试连通性成功后,进入到数据开发界面,开始新建 Hana 相关通道任务。
新建任务方式详见离线数据同步。
3.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 Hana 离线读通道任务。
3.3.1 Hana 离线读
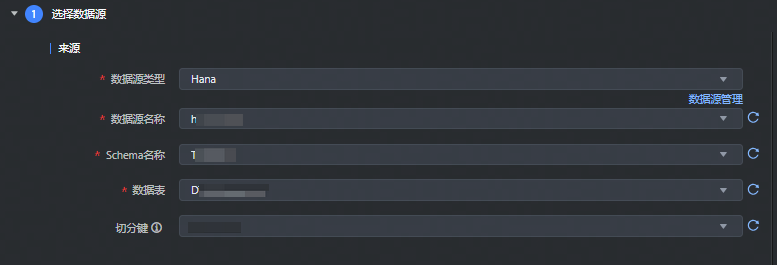
数据来源选择 Hana,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 Hana 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 Hana 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 说明 如果需要同步计算视图、属性视图等特殊视图时,则需要选择 _SYS_BIC。 |
*数据表 | 选择需要采集的数据表、视图或 Hana 特殊的计算视图、属性视图等名称信息。 |
切分建 | 根据配置的字段进行数据分片:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 |
3.3.2 Hana 离线写
数据目标端选择 Hana,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 Hana。 |
*数据源名称 | 已在数据源管理界面注册的 Hana 数据源,下拉可选。 |
*Schema 目录 | 数据库下已有的 Schema 目录信息,下拉可选。 |
*数据表 | 数据源下所属需数据写入的表名,下拉可选。 |
写入前准备语句 | 在执行该数据集成任务前,需要率先执行的 SQL 语句,通常是为了使任务重跑时支持幂等。 说明 可视化通道任务配置中只允许执行一条写入前准备语句。 |
写入后准备语句 | 执行数据同步任务之后执行的 SQL 语句。例如写入完成后插入某条特殊的数据,标志导入任务执行结束。 说明 可视化通道任务配置中只允许执行一条写入后准备语句。 |
*数据写入方式 | 下拉选择数据写入 Hana 的方式:
|
3.3.3 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
字段映射支持选择基础模式和转换模式配置映射:
说明
基础模式和转换模式不支持互相切换,模式切换后,将清空现有字段映射中所有配置信息,一旦切换无法撤销,需谨慎操作。
转换模式:
字段映射支持数据转换,您可根据实际业务需求进行配置,将源端采集的数据,事先通过数据转换后,以指定格式输入到目标端数据库中。
转换模式详细操作说明详见4.1 转换模式
在转换模式中,你可依次配置:来源节点、数据转换、目标节点信息:配置节点
说明
来源节点
配置数据来源 Source 节点信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据来源字段信息。
配置完成后,单击确认按钮,完成来源节点配置。
数据转换
单击数据转换右侧添加按钮,选择 SQL 转换方式,配置转换信息和规则:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- SQL 脚本:输入 SQL 脚本转换规则,目前仅支持添加一个转换的 SQL 语句,且不能包括 “;”。
配置完成后,单击确认按钮,完成数据转换节点配置。SQL 脚本示例详见4.1.2 添加转换节点。
目标节点
配置目标节点 Sink 信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据目标字段信息。
配置完成后,单击确认按钮,完成目标节点配置。
基础模式:
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
3.4 DSL 配置说明
Hana 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 Hana Reader 参数脚本代码,来运行数据集成任务。
3.4.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
3.4.2 Hana Reader
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,Hana Reader 脚本示例如下:
{ "job": { "common": { ... }, "reader": { "type": "hana", "datasource_id": null, "class": "com.bytedance.dts.batch.jdbc.SapHanaInputFormat", "connections": [ { "slaves": [ { "host": "xxx.xxx.xx.xxx", "db_url": "jdbc:sap://xxx.xxx.xx.xxx:39017/SystemDB", "port": 39017 } ], "shardNumber": 0 } ], "user_name": "***", "password": "***", "db_name":"_SYS_BIC", "table_schema" : "_SYS_BIC", "table_name": "VIEW_TEST/SQL_TEST_SCORE_VIEW1", "hana_view_placeholder": "PLACEHOLDER.\"$$IN_CALMONTH$$\" => '202305'", "filter": "STUDENTID > 5", "columns" :[ { "name":"STUDENTID", "type":"integer" }, { "name":"SCORE", "type":"integer" } ] }, "writer": { ... } } }
Reader 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名称 | 参数含义 |
|---|---|
*type | 数据源类型,输入 Hana 类型的 Reader type,默认固定值填写:hana |
*datasource_id | 填写注册的 Hana 数据源ID,可以在项目控制台 > 数据源管理界面中查找。
|
*class | hana reader connector type,默认固定值填写:com.bytedance.dts.batch.jdbc.SapHanaInputFormat |
*connections | jdbc 类型数据源通用配置:
|
*user_name | 有权限访问数据库的用户名信息。 |
*password | 用户名对应的密码信息。 |
*columns | 所配置的表中,需要同步的列名集合,使用 JSON 的数组描述字段信息。 |
*db_name | 填写需读取的数据库名称。 |
*table_schema | 填写需读取的 Hana 数据库中 Schema 名称。 |
*table_name | 输入需同步的数据表或者视图名字信息。 |
hana_view_placeholder | 采集带参数的计算视图时使用。 |
filter | 同步数据的过滤条件,同步数据时只会同步符合过滤条件的数据。 |
3.4.3 Hana Writer
目前暂不支持 DSL 模式配置离线数据写入 Hana,敬请期待。
3.5 高级参数说明
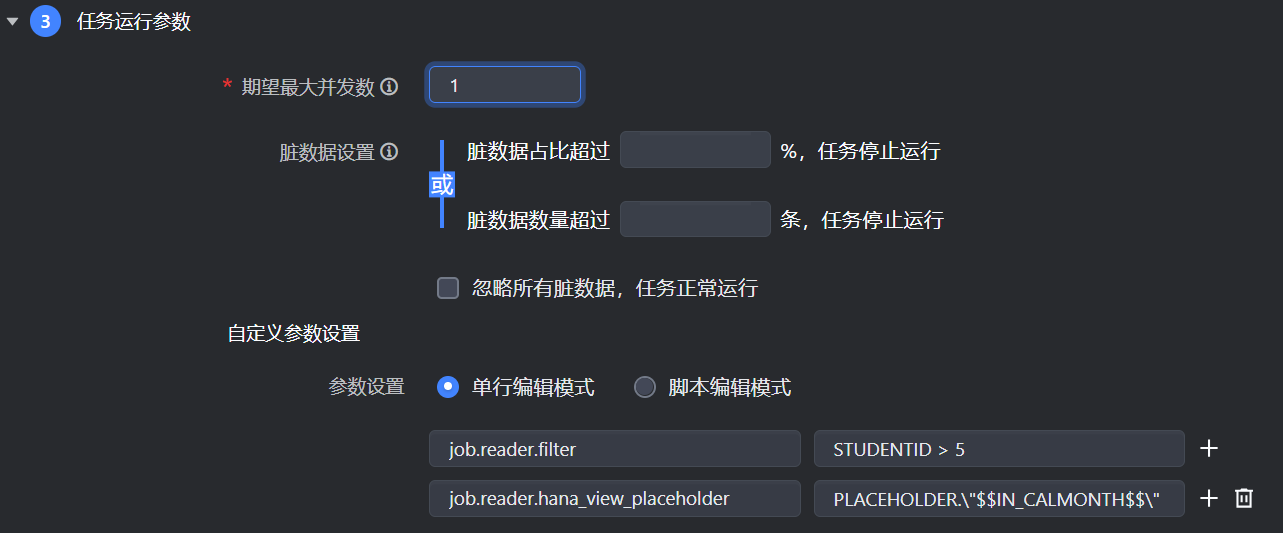
对于可视化配置通道任务,配置运行高级参数时,需在参数名称前加上 job.reader. 前缀。
如离线方式读取 Hana 数据,如果同步带参数的计算视图,且需要过滤数据读取时,则您可以使用以下高级参数:job.reader.filter、job.reader.hana_view_placeholder 如下图所示: