配置 Kafka 数据源
最近更新时间:2024.05.17 11:22:40
首次发布时间:2022.09.15 17:46:56
Kafka 数据源为您提供实时读取和离线读写 Kafka 的双向通道能力,实现不同数据源与 Kafka 数据源之间进行数据传输。
本文为您介绍 DataSail 的 Kafka 数据同步的能力支持情况。
1 支持的 Kafka 版本
- 实时读、离线读写:
- 支持火山引擎 Kafka 实例和自建 Kafka 集群,Kafka 0.10 和 2.x 版本以上的集群连接,如 Kafka 2.2.0 版本及其以后的版本均支持读取。
- 鉴权模式支持普通鉴权和 SSL 鉴权模式。
2 使用限制
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员。
- Kafka 数据源目前支持可视化配置实时读取和离线读写 Kafka。
- 为确保同步任务使用的独享集成资源组具有 Kafka 库节点的网络访问能力,您需将独享集成资源组和 Kafka 数据库节点网络打通,详见网络连通解决方案。
- 若通过 VPC 网络访问,则独享集成资源组所在 VPC 中的 IPv4 CIDR 地址,需加入到 Kafka 访问白名单中:
- 确认集成资源组所在的 VPC:
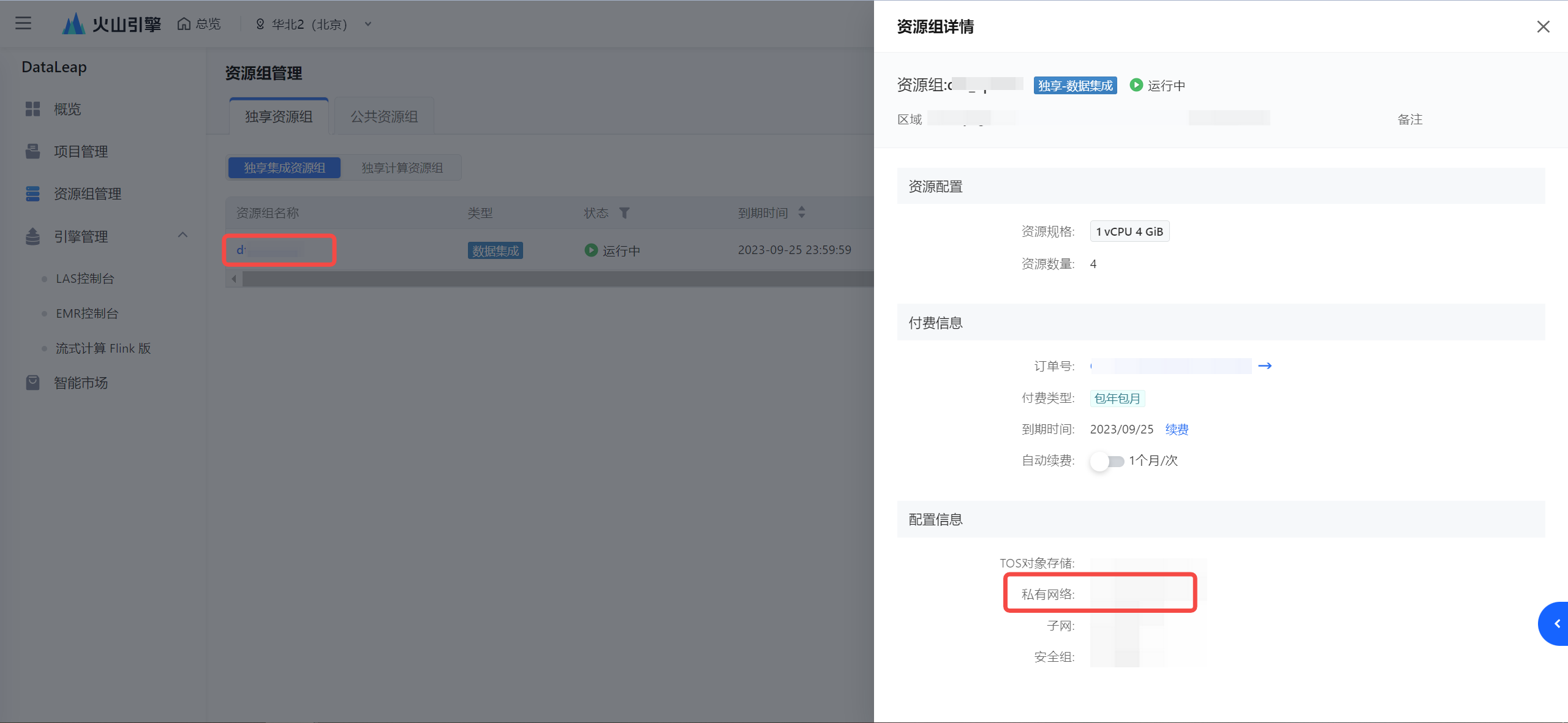
- 查看 VPC 的 IPv4 CIDR 地址:
注意
若考虑安全因素,减少 IP CIDR 的访问范围,您至少需要将集成资源组绑定的子网下的 IPv4 CIDR 地址加入到实例白名单中。
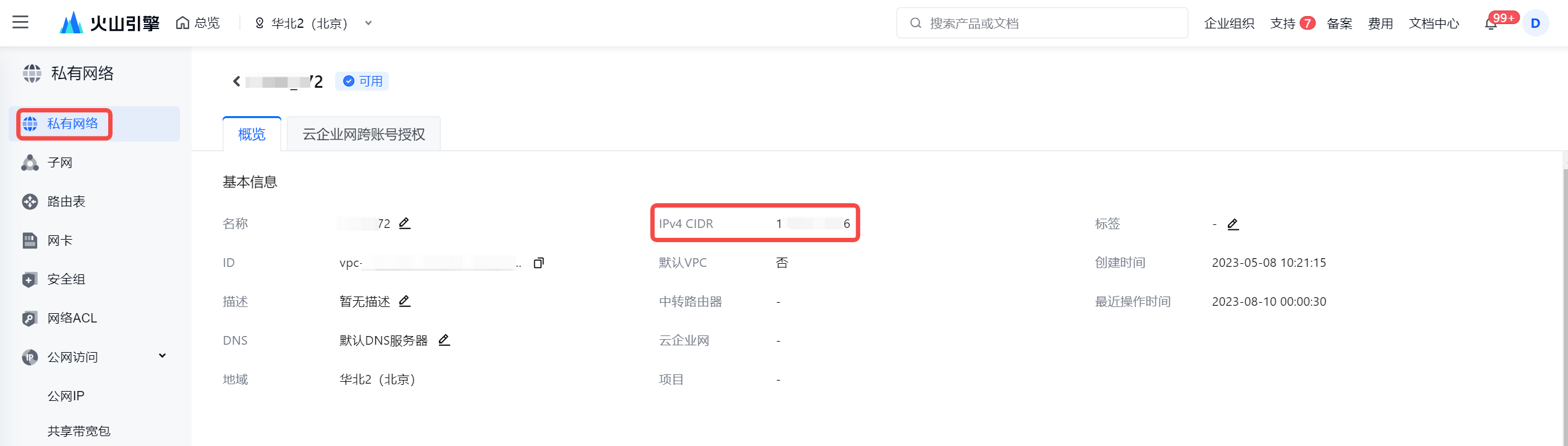
- 将获取到的 IPv4 CIDR 地址添加进 Kafka 实例白名单中。
- 确认集成资源组所在的 VPC:
- 若是通过公网形式访问 Kafka 实例,则您需进行以下操作:
- 独享集成资源组开通公网访问能力,操作详见开通公网。
- 并将公网 IP 地址,添加进 Kafka 实例白名单中。
3 支持的字段类型
目前支持的数据类型是根据数据格式来决定的,支持以下两种格式:
JSON 格式:
{ "id":1, "name":"demo", "age":19, "create_time":"2021-01-01", "update_time":"2022-01-01" }Protobuf(PB) 格式:
syntax = "proto2"; message pb1 { optional string a = 1; optional pb2 b = 2; optional int32 c = 3; message pb2 { optional string x = 1; repeated int32 y = 2; optional pb3 z = 3; } message pb3 { optional string j = 1; repeated int32 k = 2; } }
4 数据同步任务开发
4.1 数据源注册
新建数据源操作详见配置数据源,以下为您介绍不同接入方式的 Kafka 数据源配置相关信息:
火山引擎 Kafka 接入方式
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。参数说明
基本配置
*数据源类型
Kafka
*接入方式
火山引擎 Kafka
*数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
*Kafka 实例 ID
下拉选择已在火山引擎消息队列 Kafka 中创建的 Kafka 实例名称信息。
若您还未创建 Kafka 实例,您可前往 Kafka 实例控制台中创建,详见创建实例。连接串形式接入
用连接串形式配置 Kafka 数据源,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。参数说明
基本配置
*数据源类型
Kafka
*接入方式
火山引擎 Kafka
*数据源名称
数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。
参数配置
*Kafka 版本
Kafka 版本,下拉可选。当前支持 Kafka 2.2.x 和 0.10 版本。
*Kafka 集群地址
启动客户端连接Kafka服务时使用。
填写格式为 ip:port 或 host:port 格式,存在多个时,可用逗号分隔。如localhost:2181,localhost:2182*认证方式
支持 SASL_PLAINTEXT、SASL_SSL 认证方式,您也可选择 None 不认证。
选择 SASL_PLAINTEXT、SASL_SSL 认证方式时,需确认 Sasl 机制,目前支持选择 PLAIN、SCRAM-SHA-256 认证机制。*用户名
输入有权限访问 Kafka 集群环境的用户名信息。
*密码
输入用户名对应的密码信息。
扩展参数
配置 Kafka 额外需要的扩展参数信息。
如 Kafka 数据源通过公网形式接入,且开启 SASL_SSL 认证时,可将认证证书信息配置到扩展参数中,固定配置参数如下:说明
开启 SASL_SSL 后,还需在任务运行高级参数中配置 job.common.skip_dump_parse:true。详见5.2 高级参数列表。
{ "ssl.truststore.certificates":"QmFnIEF0dHJpYnV0ZXMKICAgIGZyaWVuZGx5TmFtZTogY2Fyb290CiAgICAyLjE2Ljg0MC4xLjExMzg5NC43NDY4NzUuMS4xOiA8VW5zdXBwb3J0ZWQgdGFnIDY+CnN1YmplY3Q9L0M9Q04vU1Q9QmVpamluZy9MPUJlaWppbmcvTz1BbGliYWJhL0NOPUFsaUthZmthCmlzc3Vlcj0vQz1DTi9TVD1CZWlqaW5nL0w9QmVpamluZy9PPUFsaWJhYmEvQ049QWxpS2Fma2EKLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUZLakNDQXhJQ0NRQ2RrVitpTC9jQlR6QU5CZ2txaGtpRzl3MEJBUXNGQURCV01Rc3dDUVlEVlFRR0V3SkQKVGpFUU1BNEdBMVVFQ0F3SFFtVnBhbWx1WnpFUU1BNEdBMVVFQnd3SFFtVnBhbWx1WnpFUU1BNEdBMVVFQ2d3SApRV3hwWW1GaVlURVJNQThHQTFVRUF3d0lRV3hwUzJGbWEyRXdJQmNOTWpJd05URXhNVEF6T1RNeFdoZ1BNakV5Ck1qQTBNVGN4TURNNU16RmFNRll4Q3pBSkJnTlZCQVlUQWtOT01SQXdEZ1lEVlFRSURBZENaV2xxYVc1bk1SQXcKRGdZRFZRUUhEQWRDWldscWFXNW5NUkF3RGdZRFZRUUtEQWRCYkdsaVlXSmhNUkV3RHdZRFZRUUREQWhCYkdsTApZV1pyWVRDQ0FpSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnSVBBRENDQWdvQ2dnSUJBTDMxNWFwRVJjcEFrREFCClNZNEEyYkdyUlpPNENYajRudnFid0VaNTBmMUhsd0FCanpVTUtYRVM3bFdyT3dybnFaalNJZ201d29xdStQcjQKc1doS0ZITjE5U1NuamVLaWxRb0w4U3pNazBwMjJRSksyc3FLUk11SHRvQnRMNnVPVCt5a1YxNklFZzBmWTJVdQovb1gvc0YyTEFWQ0lsMUlHYzJIVktVcjU2YzAvbU02VjZVcjVTdW03Y3RLazJkbTZZUzVnd0RPWGNxQWFaaHdkCmpWenFMRVc4aG1zTVM3bitkMi9OSUpNcVh2VEhEUlE3NHhoUjl0TjJ3OTJrZUVCR09Rb01HL1F3MFJ2UzFhUWkKUktwTnB2Q0U3ejU0M2lzdFl1RmJGamk2NDZ1NmtSQ3I3STJpNFJ3VjBxWFZNMWRqY1MrUHlzVXNJWDRtRWpkUApLcTBGcHR6c2lpM2FlVEZ1TnN3T2xvNUdpZUUzcHNWb3ltSVAySFdkNnhtbG1GYVgzWjhOZDRQeEE2aDB1UklZCnRSYkxrSHc4V2ZPQWw0ZFh4V1FGa2J2TllOTFJCNXhaVVlqbTNDQStaaFlmSlJ0TmxQYTIyNDdQc25idXA2Q0gKazNEUCthRXhkTG1idHl1Z1pPL2xOcWk5V01aMHFMRkdYWkR6OGFzdGdKUEdLaUNqaWhjY3BQMWNkekdsQ3pHdQppRTZTMjVKRUJ1WFBsNHdnNEdYTnVDZzZ0Y0VLTDJxaW52YnJDaW1yaWxXdUZhakJoN2hSSDBkZ2toZXp3NnhVCiszKytaQ2ViRUpPWFo4YnluM3YvZ215eDJQRG5LbEJQY1hDeTIzbmFkYmlYL3pwTnZOdkNxQWV3YWptOUFsV1kKZlhiQ2w1VGtVbnlNUHNoMHJ3V2VlUllSMmtNM0FnTUJBQUV3RFFZSktvWklodmNOQVFFTEJRQURnZ0lCQUR4VwpZSm9XaDlEVnR3RkdwOFRPcmxiWjdrd2ZsS0Z2OEhldzRTWDAwSzVHd0tnbW5uM2ZqZFIwRjhyWjJhci9CcWRECnpSNjNzdjlMR2pNY2k5TldBcVBxTjVNeUtCOTdLckZWNm5IemNZTFJtVCtsdG9scWNmcDVNZUdDcWthN1pURUwKdDY1OHh4YVNYTkVZOUhHSFlza0l1N21XZDQxS0FqMFJMUkpuRUVPckNTWnpmcHpHNExkRDZKMHU3d3B5SlNZTApqR3hpMnhzd3Q1QzB4NzkwTFMvSm1GcTY1Yy92emZBVGpibXU2WFNPM1V2dHNBRHBqMHBIM0ZKRmhMem9UNjdvCk5yVWVGRUhyenNNYzdKZW5ZbVBJWW1FYjR4WGxmY3RqQ3pMYWlORzN1OHVLd1hHQmsvb2FnQXdYQ3NJOEkwcFIKd3RXL1FlZFh4bEZ0VWZBVFJabkkvZUxxdko1Y1E2YVhnL0d5SnRBditjY0ZmMDA0SzFFUjAwRUNlNzM4V05YbQorNk5Oa2hONWdQaHdzZm9EaHErYTdabXZqOSt4L1hEalNScVo4aitYSU1pOVpRalR3VUFnOUptbmh5UjRlSlhuCm9RQXhHYzNpaTk4WW9Bc3BLWkdSWDZMb1JmWWJORTNUWEpzU3pHdzczK1BxUzF5NzR4Tk5tTXgyWFg2SVYvNTMKSXM1bUE4ZmxpNkJJRUtrQWdFNlBuMHQ2djVFUDZoYVZGODR2SmF6WVJJbFlmbFIybWk4cDhkVTZrb2hpQzc5QwplNHNlUlRUWmd5WFUrNWRnRklYcWFndWIyQTc5dFJ0UEFyKzRYaTg0anpZODRjZVV3cVgyZnhSd2tmYVVVSmI4CkhoMnErUCtWSmVLNTBCODNEWjR1aStXTkpiQWFBYmNMTXNuL2lkWDMKLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQpCYWcgQXR0cmlidXRlcwogICAgZnJpZW5kbHlOYW1lOiBjYXJvb3QyCiAgICAyLjE2Ljg0MC4xLjExMzg5NC43NDY4NzUuMS4xOiA8VW5zdXBwb3J0ZWQgdGFnIDY+CnN1YmplY3Q9L0M9Q04vU1Q9SFovTD1IWi9PPUFCL0NOPUthZmthQ0EvZW1haWxBZGRyZXNzPXpoZW5kb25nbGl1Lmx6ZEBhbGliYWJhLmNvbQppc3N1ZXI9L0M9Q04vU1Q9SFovTD1IWi9PPUFCL0NOPUthZmthQ0EvZW1haWxBZGRyZXNzPXpoZW5kb25nbGl1Lmx6ZEBhbGliYWJhLmNvbQotLS0tLUJFR0lOIENFUlRJRklDQVRFLS0tLS0KTUlJRFBEQ0NBcVdnQXdJQkFnSUpBTVJzYjBETE0xZnNNQTBHQ1NxR1NJYjNEUUVCQlFVQU1ISXhDekFKQmdOVgpCQVlUQWtOT01Rc3dDUVlEVlFRSUV3SklXakVMTUFrR0ExVUVCeE1DU0ZveEN6QUpCZ05WQkFvVEFrRkNNUkF3CkRnWURWUVFERXdkTFlXWnJZVU5CTVNvd0tBWUpLb1pJaHZjTkFRa0JGaHQ2YUdWdVpHOXVaMnhwZFM1c2VtUkEKWVd4cFltRmlZUzVqYjIwd0lCY05NVGN3TXpBNU1USTFNRFV5V2hnUE1qRXdNVEF5TVRjeE1qVXdOVEphTUhJeApDekFKQmdOVkJBWVRBa05PTVFzd0NRWURWUVFJRXdKSVdqRUxNQWtHQTFVRUJ4TUNTRm94Q3pBSkJnTlZCQW9UCkFrRkNNUkF3RGdZRFZRUURFd2RMWVdacllVTkJNU293S0FZSktvWklodmNOQVFrQkZodDZhR1Z1Wkc5dVoyeHAKZFM1c2VtUkFZV3hwWW1GaVlTNWpiMjB3Z1o4d0RRWUpLb1pJaHZjTkFRRUJCUUFEZ1kwQU1JR0pBb0dCQUxaVgpiYklPMVVMUVFOODUzQlRCZ1JmUGlSSmFBT1dmMzh1OEdDMFROcC9FOXF0STg4QSs3OXl3QVAxN2s1V1lKN1hTCndYTU9KM2gxcWtRVDJUWUpWZXRaNkU2OUNVSnE0QnNPdk5sTlJ2bW5XNmVGeW1oNVFac0V6Mk1Ub294SmpWakMKSlFQbEkyWFJEaklyVFZZRVFXVUR4ajJKaEI4VlZQRWVkKzZ1NEtRVkFnTUJBQUdqZ2Rjd2dkUXdIUVlEVlIwTwpCQllFRkhGbE9vaXFReFhhblZpMkdVb0RpS0REMzN1ak1JR2tCZ05WSFNNRWdad3dnWm1BRkhGbE9vaXFReFhhCm5WaTJHVW9EaUtERDMzdWpvWGFrZERCeU1Rc3dDUVlEVlFRR0V3SkRUakVMTUFrR0ExVUVDQk1DU0ZveEN6QUoKQmdOVkJBY1RBa2hhTVFzd0NRWURWUVFLRXdKQlFqRVFNQTRHQTFVRUF4TUhTMkZtYTJGRFFURXFNQ2dHQ1NxRwpTSWIzRFFFSkFSWWJlbWhsYm1SdmJtZHNhWFV1Ykhwa1FHRnNhV0poWW1FdVkyOXRnZ2tBeEd4dlFNc3pWK3d3CkRBWURWUjBUQkFVd0F3RUIvekFOQmdrcWhraUc5dzBCQVFVRkFBT0JnUUJUU3owNHAwQUpYS2wzMHNIdytVTS8KL2sxakdGSnpJNXAwWjZsMkp6S1FZUFAzUGZFL2JpRTgvcm1pR1lFZW5OcVdOeTFaU25pRUh3YThML1V4OThjaQo0SDBaU3BVck1vMis2YmZ1Tlc5WDM1Q0ZQcDV2WVlKcWZ0aWxKQktJSlgzQzNKMXJ1T3VCUjI4VXhFNDJ4eDRLCnBRNzB3Q2hOaTkxNGM0QitTeGtHVWc9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==", "ssl.truststore.type":"PEM", "ssl.endpoint.identification.algorithm":"" }
4.2 新建离线任务
Kafka 数据源测试连通性成功后,进入到数据开发界面,开始新建 Kafka 相关通道任务。新建任务方式详见离线数据同步、流式数据同步。
4.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 Kafka 离线读、Kafka 离线写或 Kafka 流式读等通道任务。
4.3.1 Kafka 离线读
数据来源选择 Kafka,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 数据来源类型选择 Kafka。 |
*数据源名称 | 已在数据源管理界面注册的 Kafka 数据源,下拉可选。 |
*Topic 名称 | 选择 Kafka 处理消息源的分类主题名称,下拉可选数据源下对应需读取数据的 Topic 名称。 注意 需检查对应的 Group ID 是否存在,且 Group ID 命名规则需严格符合:dorado_{任务名称}_{任务id},否则任务会失败。 |
消费组 ID | 指定 Kafka 消费组 ID 信息,如果不指定该参数,则默认设定 group.id=dorado_${作业名称}_${作业id} |
*数据类型 | 支持 JSON、CSV 类型,下拉可选,默认为 JSON 格式。 |
示例数据 | 数据格式为 json 时,需以 json 字符串形式描述 schema。必须填写完整的数据,否则 schema 不准确。 |
*分隔符 | 数据格式为 csv 时,需添加数据分隔符参数,下拉可选择原始文件的分隔符,如“,”、“Tab”、“;”等,同时也支持自定义分隔符的方式指定。 |
*周期起始位点 | 任务周期运行时,每次读取 kafka 的开始位点,可通过指定时间、指定时间戳、指定位点、分区起始位点四种方式来指定周期读取的起始位点。 |
*起始时间/指定时间戳/起始位点值 | 根据选择的周期起始位点方式,可通过不同形式设置位点值:
|
*周期结束位点 | 任务周期运行时,每次读取 kafka 的结束位点,可通过指定时间、指定时间戳、指定位点、分区最新位点四种方式来指定周期读取的结束位点。 |
*结束时间/指定时间戳/结束位点值 | 根据选择的周期结束位点方式,可通过不同形式设置位点值:
|
4.3.2 Kafka 离线写
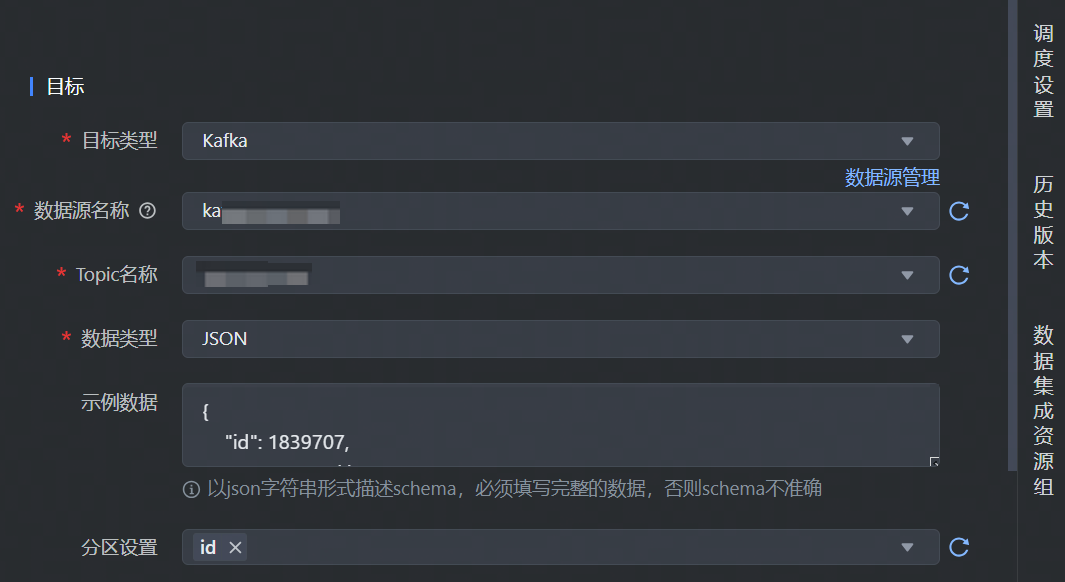
数据目标端选择 Kafka,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*目标类型 | 数据去向目标类型选择 Kafka。 |
*数据源名称 | 已在数据源管理界面注册的 Kafka 数据源,下拉可选。 |
*Topic名称 | 选择 Kafka 处理消息源的不同分类主题名称,下拉可选数据源下对应需写入数据的 Topic 名称。 |
*数据格式 | 默认仅支持 json 格式,不可编辑。 |
示例数据 | 需以 json 字符串形式描述 schema。必须填写完整的数据,否则schema不准确。 |
分区设置 | 可以自定义 Kafka 分区规则,从 Kafka message 字段中选择 0~N 个字段,用于保证指定字段相同的值写入到 Kafka 的同一 partition 中。 |
4.3.3 Kafka 流式读
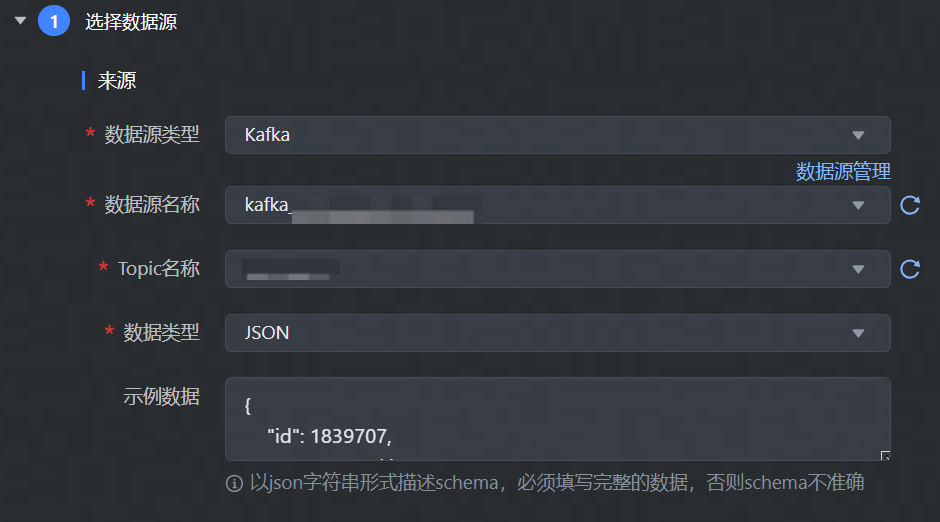
数据来源选择 Kafka,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 数据来源类型选择 Kafka。 |
*数据源名称 | 已在数据源管理界面注册的 Kafka 数据源,下拉可选。 |
*Topic 名称 | 选择 Kafka 处理消息源的不同分类主题名称,下拉可选数据源下对应需读取数据的 Topic 名称,支持同时选择多个结构相同的 Topic。 |
*数据类型 | 支持 JSON、Pb,下拉可选,默认为JSON格式。 |
示例数据 | 数据格式为 json 时,需以 json 字符串形式描述 schema。必须填写完整的数据,否则schema不准确。 |
*Pb 类定义 | 数据格式为 Pb 时,需要先定义 Pb 类,在框中中填写 Pb 的
|
*Pb 类名 | 数据格式为 Pb 时,需要填写 PB Class 入口类名信息, |
4.3.4 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
字段映射支持选择基础模式和转换模式配置映射:
说明
基础模式和转换模式不支持互相切换,模式切换后,将清空现有字段映射中所有配置信息,一旦切换无法撤销,需谨慎操作。
转换模式:
字段映射支持数据转换,您可根据实际业务需求进行配置,将源端采集的数据,事先通过数据转换后,以指定格式输入到目标端数据库中。
转换模式详细操作说明详见4.1 转换模式
在转换模式中,你可依次配置:来源节点、数据转换、目标节点信息:配置节点
说明
来源节点
配置数据来源 Source 节点信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据来源字段信息。
配置完成后,单击确认按钮,完成来源节点配置。
数据转换
单击数据转换右侧添加按钮,选择 SQL 转换方式,配置转换信息和规则:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- SQL 脚本:输入 SQL 脚本转换规则,目前仅支持添加一个转换的 SQL 语句,且不能包括 “;”。
配置完成后,单击确认按钮,完成数据转换节点配置。SQL 脚本示例详见4.1.2 添加转换节点。
目标节点
配置目标节点 Sink 信息:
- 节点名称:自定义输入来源节点名称信息,只允许由数字、字母、下划线、-和.组成;且长度不能超过10。
- 数据字段:通过自动添加、手动添加等方式添加数据目标字段信息。
配置完成后,单击确认按钮,完成目标节点配置。
基础模式:
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
4.4 DSL 配置说明
Kafka 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 Kafka Reader 参数脚本代码,来运行数据集成任务。
4.4.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
4.4.2 DSL 配置 Kafka 流式读
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,Kafka 流式读脚本示例如下:
{ "version": "0.2", "type": "stream", "reader": { "type": "kafka_volc", "datasource_id": null, "parameter": { "connector":{ "connector":{ "owner":"Account/xxxxxx", "topic":"topic_name", "startup-mode":"latest-offset", "bootstrap":{ "servers":"kafka-cnxxxxxxrk.kafka.ivolces.com:9092" }, // "version":"0.10", "group":{ "id":"group_id_test" } }, "update-mode":"append" }, "child_connector_type":"kafka220", "columns": [ { "upperCaseName": "ID", "name": "id", "type": "BIGINT" }, { "upperCaseName": "NAME", "name": "name", "type": "VARCHAR" }, { "upperCaseName": "PRICE", "name": "price", "type": "DOUBLE" }, { "upperCaseName": "LIST_INFO", "name": "list_info", "type": "VARCHAR" }, { "upperCaseName": "EVENT_TIME", "name": "event_time", "type": "BIGINT" }, { "upperCaseName": "ADDRESS", "name": "address", "type": "VARCHAR" }, { "upperCaseName": "MAP_INFO", "name": "map_info", "type": "VARCHAR" }, { "upperCaseName": "CREATE_TIME", "name": "create_time", "type": "BIGINT" } ], "enable_source_parser": "true", "class":"com.bytedance.dts.dump.dataplugin.source.mq.Kafka020SourceFunctionDAGBuilder" } }, "writer": { "type": "hbase", "datasource_id": null, "parameter": { "hbase_conf":{ "hbase.zookeeper.quorum":"hb-cxxxxxx-zk.config.config.volces.com:2181", "hbase.zookeeper.property.clientPort":"2181", "zookeeper.znode.parent":"/hbase/hb-cxxxxxxx7e", "hbase.rootdir":"/hbase/hb-cxxxxxxx7e", "hbase.cluster.distributed":true }, "format.type":"json", "columns":[ { "upperCaseName":"CF:ID", "name":"cf:id", "type":"bigint" }, { "upperCaseName":"CF:NAME", "name":"cf:name", "type":"string" }, { "upperCaseName":"CF:PRICE", "name":"cf:price", "type":"double" }, { "upperCaseName":"CF:LIST_INFO", "name":"cf:list_info", "type":"string" }, { "upperCaseName":"CF:EVENT_TIME", "name":"cf:event_time", "type":"bigint" }, { "upperCaseName":"CF:ADDRESS", "name":"cf:address", "type":"string" }, { "upperCaseName":"CF:MAP_INFO", "name":"cf:map_info", "type":"string" }, { "upperCaseName":"CF:CREATE_TIME", "name":"cf:create_time", "type":"bigint" } ], "class":"com.bytedance.dts.batch.hbase.HBaseOutputFormat", "table":"default:hbase_xxxxxxxtest_one", "row_key_column":"$(cf:id)", "writer_parallelism_num":2 } }, "common": { "parameter": { "global_parallelism_num": 1, "dirty_record_skip_enabled": "false", "checkpoint_interval": 180000 } } }
Kafka 流式读参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 参数说明 | 样例&详细说明 |
|---|---|---|
*datasource_id | 注册的 Kafka 数据源 ID。可以在项目控制台 > 数据源管理界面中查找 | 若通过 Kafka 连接串信息配置时,可以不填 datasource_id 信息,将其设置为 null |
*topic | Kafka 消费的 topic 列表,可填写多个 topic,用英文逗号隔开 | topic1,topic2,toipic3 |
owner | 配置任务 owner 的账号信息 | Account/21xxxxxx57 |
startup-mode | 配置任务初始消费策略 | 默认:group offset 开始消费 |
bootstreap.servers | 填写 Kafka 连接串信息 | 若配置了 datasource_id 时,则可以忽略不填 |
version | Kafka broker 版本 | |
group.id | Kafka 中 group id 信息 | 若不填时,会默认按照任务名称和任务 id 拼接而成 |
update-mode | 消息更新模式 | Kafka 一般情况下配置为:append |
*child_connector_type | Kafka connector 类型 | kafka connector 一般情况下配置为:kafka220 |
*columns | kafka 消息中的字段名称及类型信息 | |
enable_source_parser | 是否用在 source 端解析消息 | kafka 场景一般为 true |
*class | 使用引擎内 kafka 的类名,有明确指定 datasource_id 后,可以忽略不填 | Kafka 需配置为: |
4.4.3 DSL 配置 Kafka 离线读
根据实际情况替换 Kafka 流式读相应参数,Kafka 流式读脚本示例如下:
// ************************************** // Author: DataLeapTest1 // CreateTime: 2024-03-12 14:46:29 // Description: // Update: Task Update Description // 变量使用规则如下: // 1.自定义参数变量: {{}}, 比如{{number}} // 2.系统时间变量${}, 比如 ${date}、${hour} // ************************************** { // [required] dsl version, suggest to use latest version "version": "0.2", // [required] exection mode, supoort streaming / batch now "type": "batch", // reader config "reader": { // [required] datasource type "type": "kafka" , // [optional] datasource id, set it if you have registered datasource "datasource_id": 6xxx4, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value // schema // "reader_parallelism_num":1, "kafka_servers":"kafka-cnxxxxxxrk.kafka.ivolces.com:9092", "content_type":"csv", "csv_delimiter":"|", "metadata_columns": "__timestamp__,__offset__,__value__", "columns":[ { "name":"__value__", "type":"string" }, { "name":"__timestamp__", "type":"bigint" }, { "name":"__offset__", "type":"bigint" }, { "upperCaseName":"ID", "name":"id", "type":"bigint" }, { "upperCaseName":"NAME", "name":"name", "type":"string" }, { "upperCaseName":"PRICE", "name":"price", "type":"double" } ], "topics":"topic_namq", "group_id":"groupname_test", // "start_timestamp": 1710407869000, // "end_timestamp": 1710408169000, // or start/end date format "start_date": "${DTF-yyyyMMddHHmm-15i}", "end_date": "${DTF-yyyyMMddHHmm}", "date_format": "yyyyMMddHHmm", "class":"com.bytedance.bitsail.connector.kafka.source.KafkaSubscribeSource" } }, "writer": { // [required] datasource type "type": "hive" , // [optional] datasource id, set it if you have registered datasource "datasource_id": 66703, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value // schema "class":"com.bytedance.dts.batch.hive.parquet.HiveParquetOutputFormat", "hive_version":"3.1.2", "emr_hive_conf": { "hive.metastore.uris": "thrift://xxx.xx.x.xx:9083,thrift://xxx.xx.x.xx:9083,thrift://xxx.xx.x.xx:9083" }, "db_name": "db_name_test", "table_name":"table_name_test", "partition": "date=20240312,hour=24", "columns": [ { "name":"meta_value", "type":"string" }, { "name":"meta_timestamp", "type":"bigint" }, { "name":"meta_offset", "type":"bigint" }, { "name": "id", "type": "bigint" }, { "name": "name", "type": "string" }, { "name": "price", "type": "double" } ] } }, // common config "common": { // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value // [optional] advanced parameters "optional": { // "key" : "value" (must be string) "leap.dts.params.image.tag": "release-c-1.25.0-qa-kafka-batch-source-testing-vci" } } } }
Kafka 离线读参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
说明
消费开始时间,可用时间戳或时间字符串形式填写,即表格中,您可选择填写 start_timestamp、end_timestamp 组合或 start_date、end_date 组合。
reader参数 | 参数说明 | 样例&详细说明 |
|---|---|---|
*kafka_servers | Kafka 连接串信息,输入的连接串信息需保证和独享集成资源组的网络连通性。配置 datasource_id 信息时,连接串信息可忽略不填。 | kafka-cnxxxxxxrk.kafka.ivolces.com:9092 |
*content_type | Kafka 消息格式,支持填写 csv、json 格式。 |
|
*csv_delimiter | 若 Kafka 消息格式为 csv 时,您需指定 csv 格式分隔符。 | |
*metadata_columns | 指定拉取 kafka 的元数据字段。 | timestamp,offset,... 说明
|
*columns | kafka 消息中的字段类型。 | 每个field以分隔符分出来的顺序对应 |
*topics | Kafka 消费的 topic 列表,可填写多个 topic,用英文逗号隔开。 | topic1,topic2,toipic3 |
*group_id | Kafka consumer group id | |
start_timestamp | 消费开始时间戳 (单位:毫秒),指定 start_date 参数后可以不用填写。 | |
end_timestamp | 消费结束时间戳(单位:毫秒),指定 end_date 参数后可以不用填写。 | |
start_date | 消费开始时间字符串,支持以时间变量形式填写,根据任务配置的调度时间,执行时解析成具体的时间,如 ${DTF-yyyyMMddHHmm-15i},更多时间变量参数详见平台时间变量与常量说明 | 时间变量表达式:${DTF-yyyyMMddHHmm-15i} ,实际执行时表达式解析为202403172345 (2024年03月17日23点45分) |
end_date | 消费结束时间字符串,同样支持以时间变量形式填写。 | 时间变量表达式:${DTF-yyyyMMddHHmm} ,实际执行时表达式解析为202403180000 (2024年03月18日00点00分) |
date_format | 时间字符串格式 | yyyyMMddHHmm ,支持配置到分钟级别的时间格式串,可自定义其他的时间格式串,详见平台时间变量与常量说明 |
*class | 固定值,保持不变 | com.bytedance.bitsail.connector.kafka.source.KafkaSubscribeSource |
*leap.dts.params.image.tag | 流式任务需要指定引擎镜像版本时,需添加的参数名称 | 固定填写:release-c-1.25.0-qa-kafka-batch-source-testing-vci |
5 流式任务运行参数说明
5.1 运行参数说明
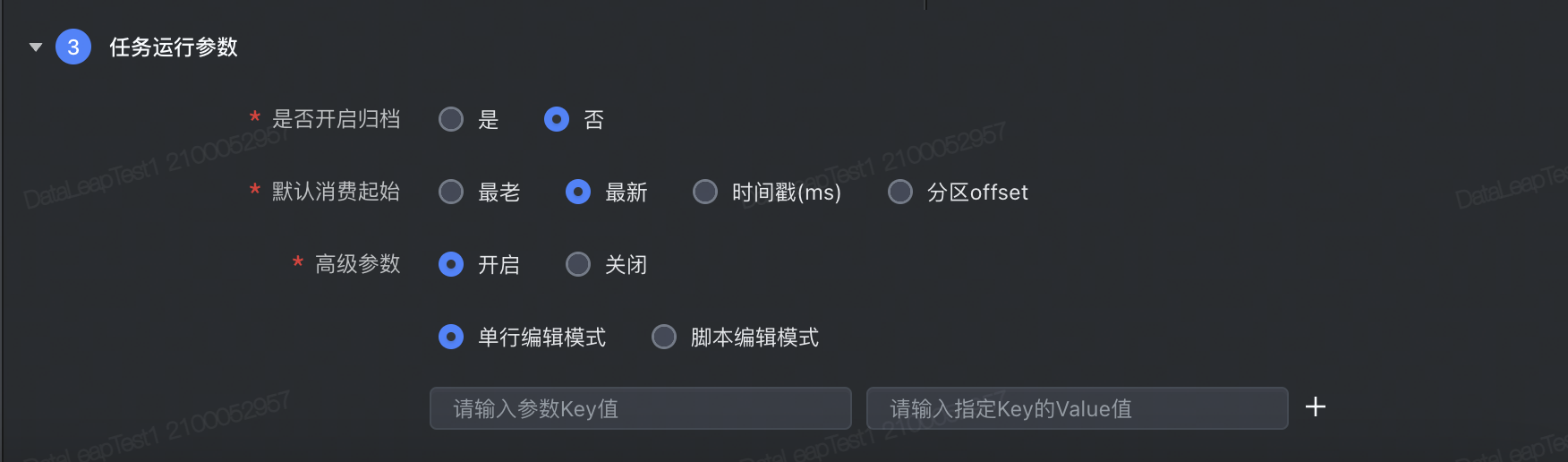
流式任务运行参数与离线任务运行参数配置属性不同,下面将为您介绍流式任务运行参数配置说明:
配置项 | 说明 |
|---|---|
是否开启归档 | 默认否,这个选项只有在目标数据源是
|
默认消费起始 | 选定消费 Kafka 的起始方式:
|
高级参数 | 读参数需要加上 |
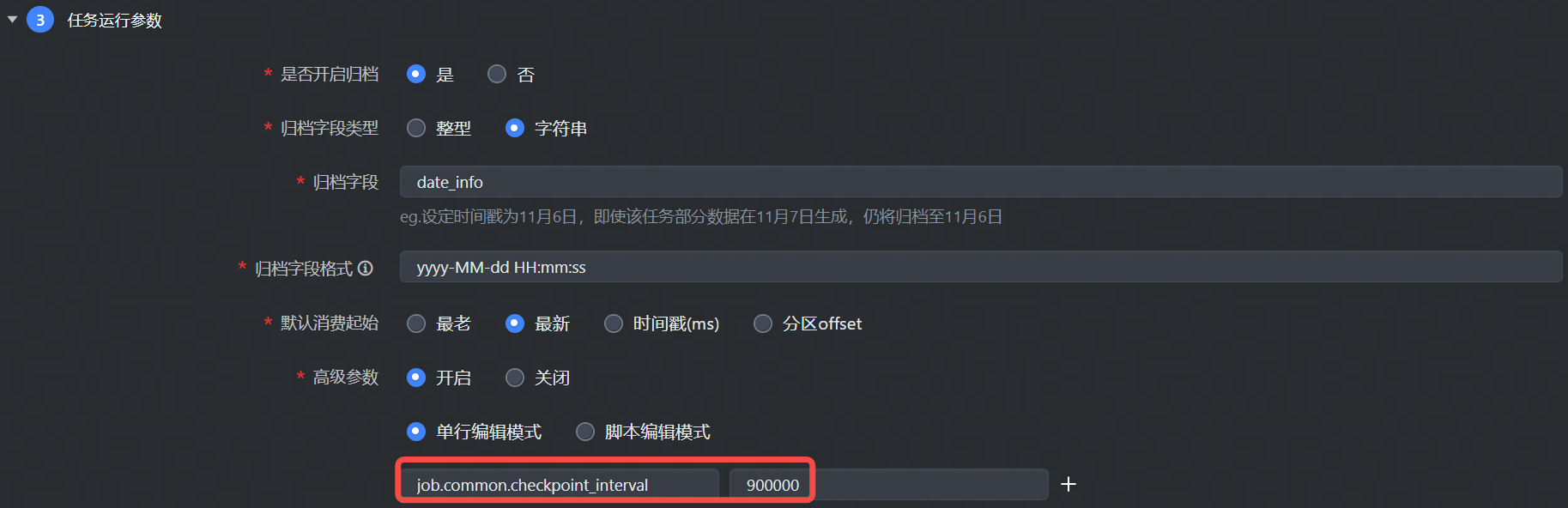
5.2 高级参数列表
参数名 | 描述 | 默认值 |
|---|---|---|
job.common.checkpoint_interval | checkpoint 的间隔,目前默认 15min 会进行一次 checkpoint。 | 900000,单位 ms |
job.common.checkpoint_timeout | Checkpoint 超时时间。 | 300000,单位:milliseconds |
job.writer.properties | max.request.size 消息体大小; 说明 适用范围:DataSail 整库解决方案配置中,如果单个消息体比较大时,可以调整此参数。 | {"max.request.size":1048576,"buffer.memory":33554432} |
job.writer.compression_type | 消息压缩格式,支持 none、snappy、gzip、lz4 说明 DataSail 整库解决方案配置中,可指定消息压缩格式。 | snappy |
job.common.skip_dump_parse | Kafka 数据源通过公网形式接入,开启 SASL_SSL 认证时,需设置该参数为 true。 | false |