[模型组]文本检测裁切识别
最近更新时间:2024.05.13 11:27:07
首次发布时间:2024.02.01 10:41:41
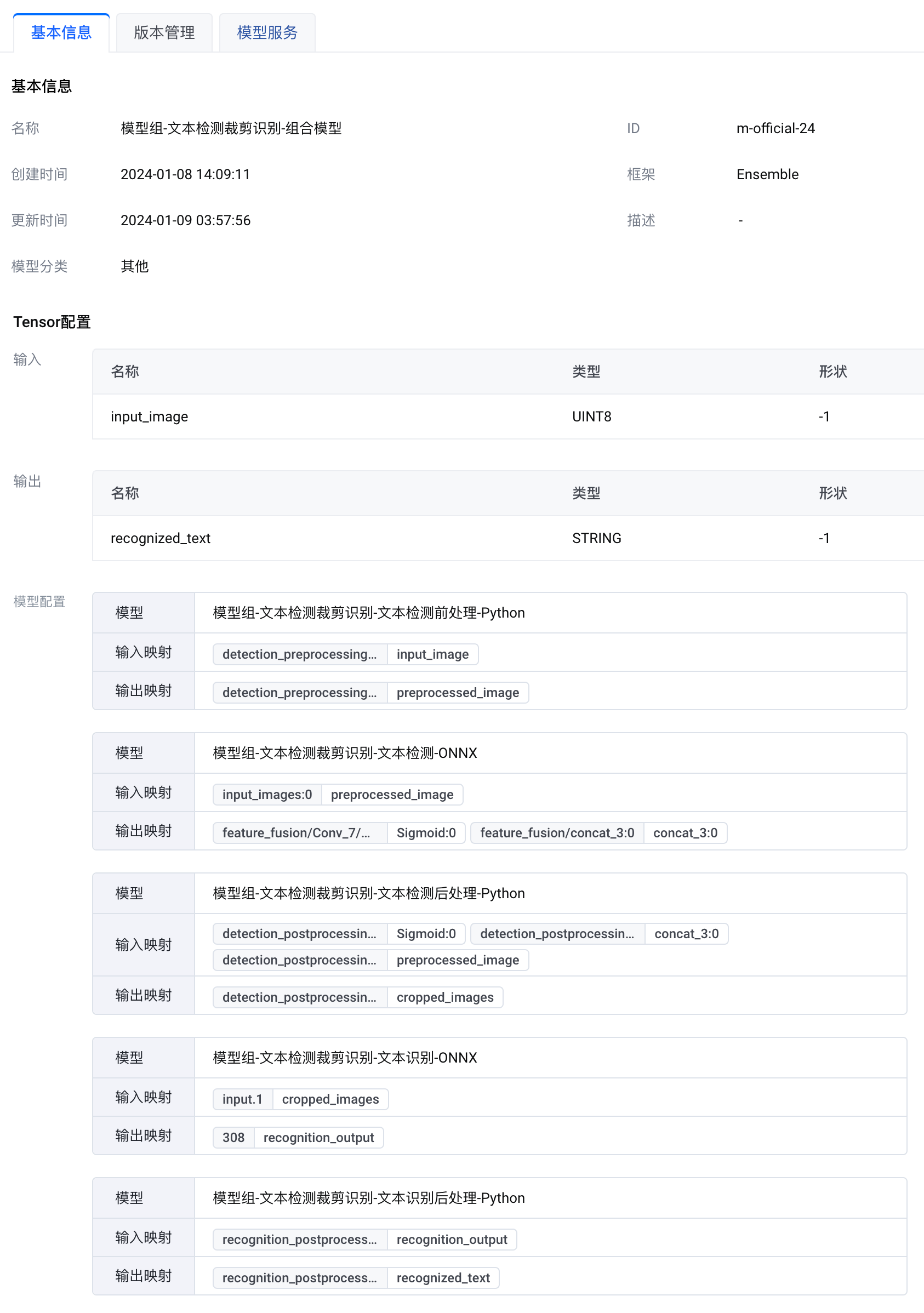
文本检测裁切识别是一个官方模型组,它包含 5 个独立模型和 1 个 Ensemble 模型。Ensemble 模型将 5 个独立模型封装为一个工作流。本模型组能够对输入图像进行文本识别,返回识别到的文本字符串。
现代机器学习系统通常需要按顺序执行多个模型,可能包括预处理步骤和聚合多个模型的结果。为了简化用户调用流程,减少网络延迟和降低带宽成本,边缘智能提供了 Ensemble 模型功能,该功能可以一次性执行多个模型。使用 Ensemble 模型,您可以封装多个模型间的数据传输和执行过程,获得更高效的网络调用。
模型组基本信息
模型列表
本模型组包含 6 个模型。其中,Ensemble 模型中封装了其他模型,定义了模型组的整体工作流,如下图所示。使用过程中,您只需部署 Ensemble 模型,无需关注中间的处理过程。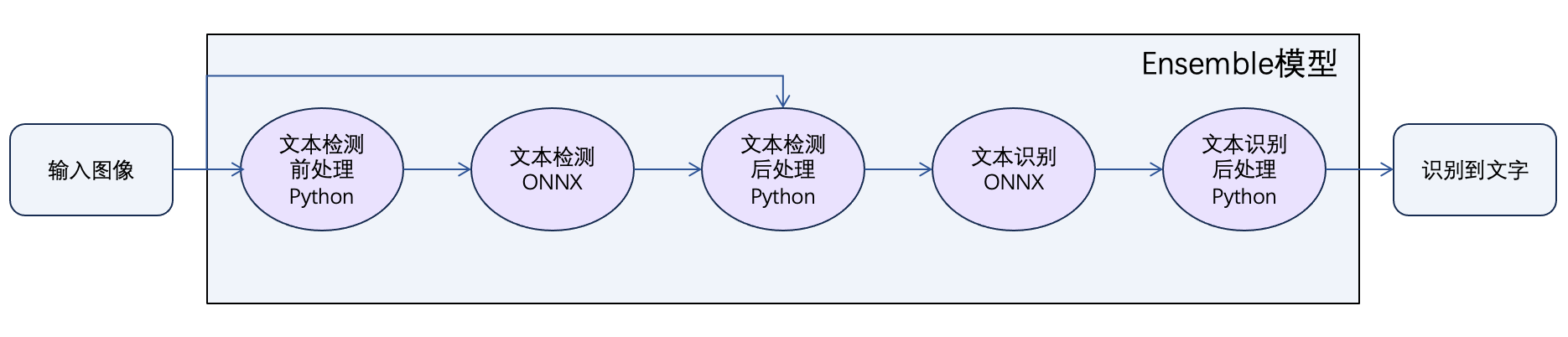
您可以在边缘智能控制台的 官方模型 列表访问本模型组所包含的具体模型。
模型名称 | 模型基本信息 |
|---|---|
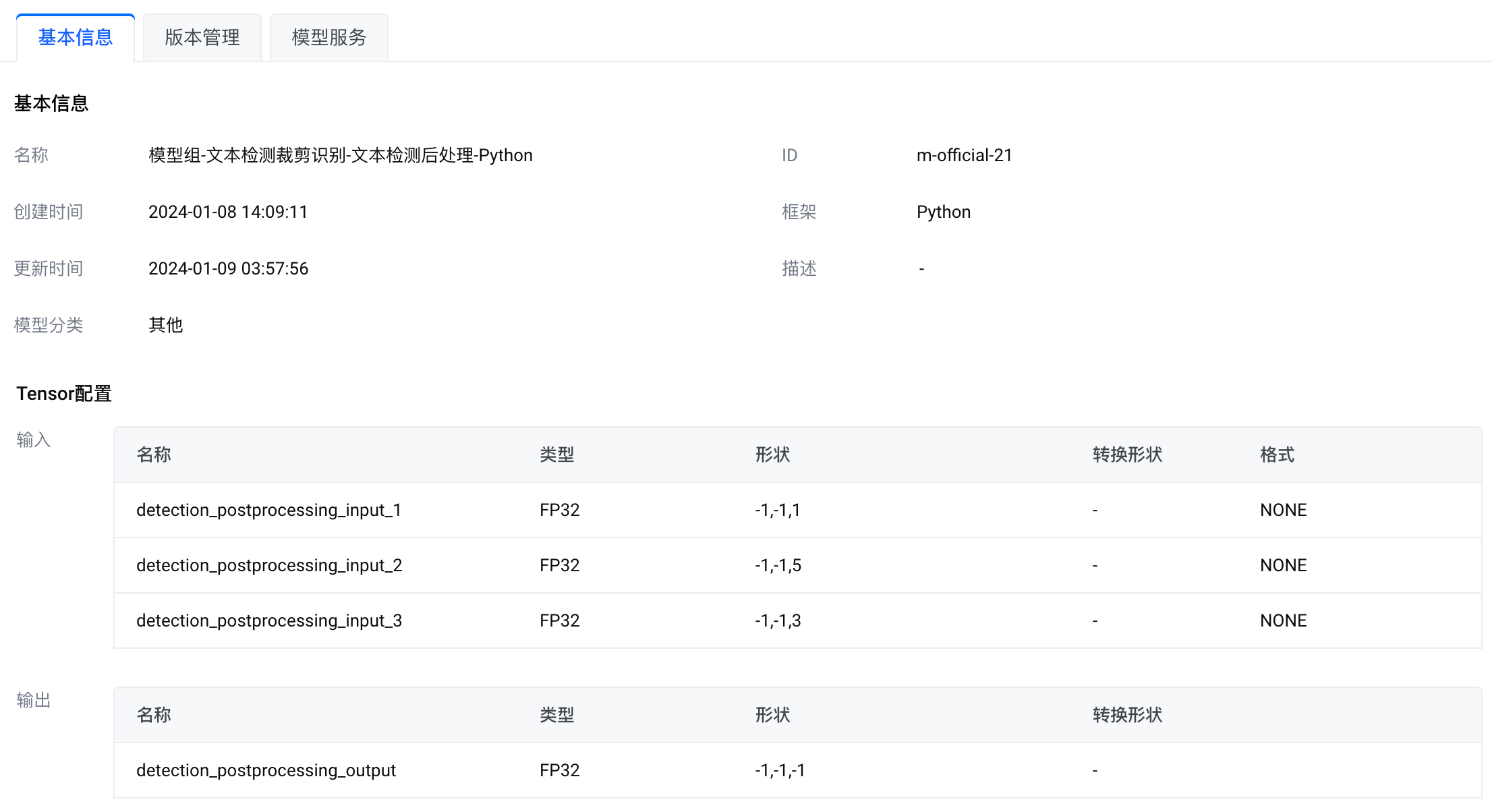
模型组-文本检测裁剪识别-文本检测后处理-Python |
|
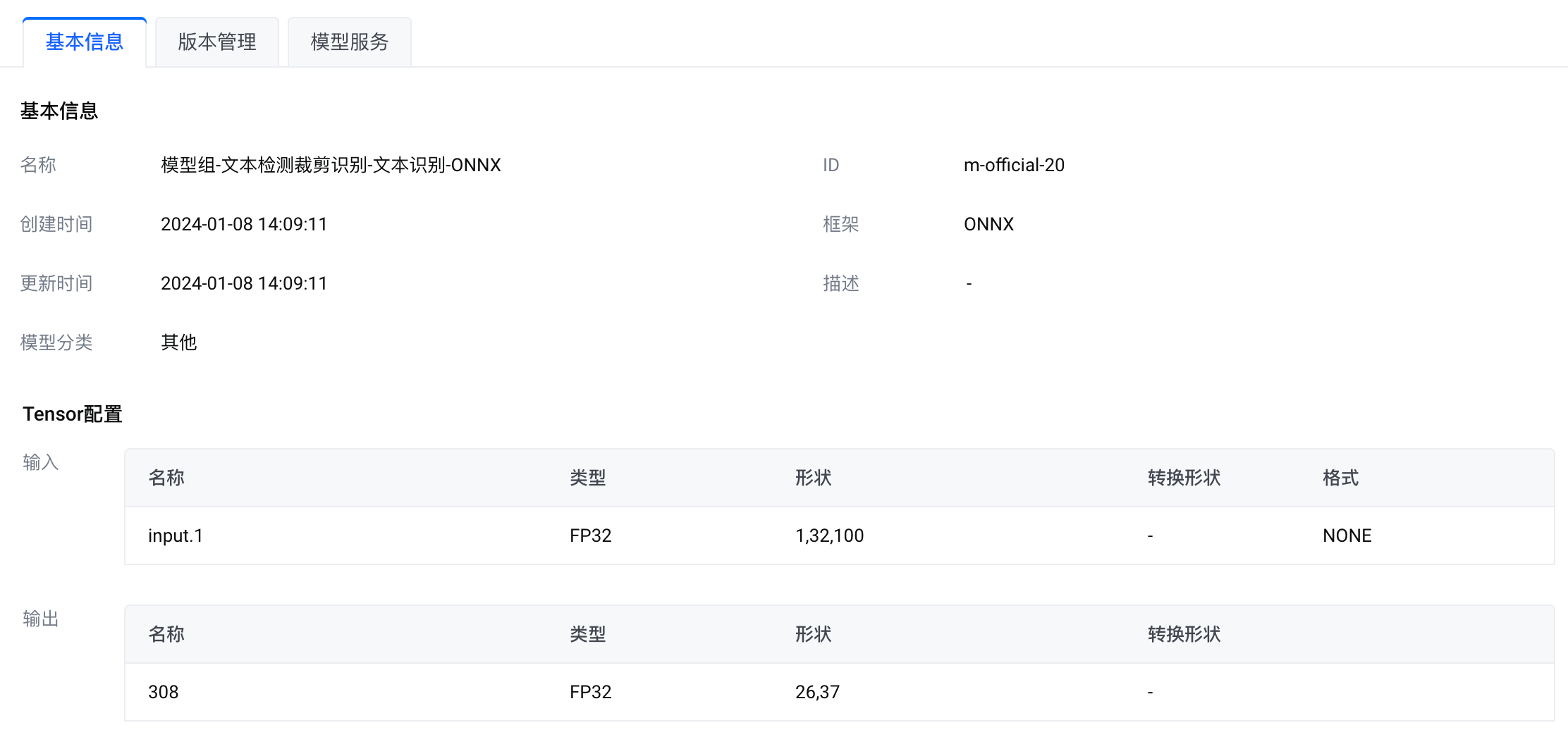
模型组-文本检测裁剪识别-文本识别-ONNX |
|
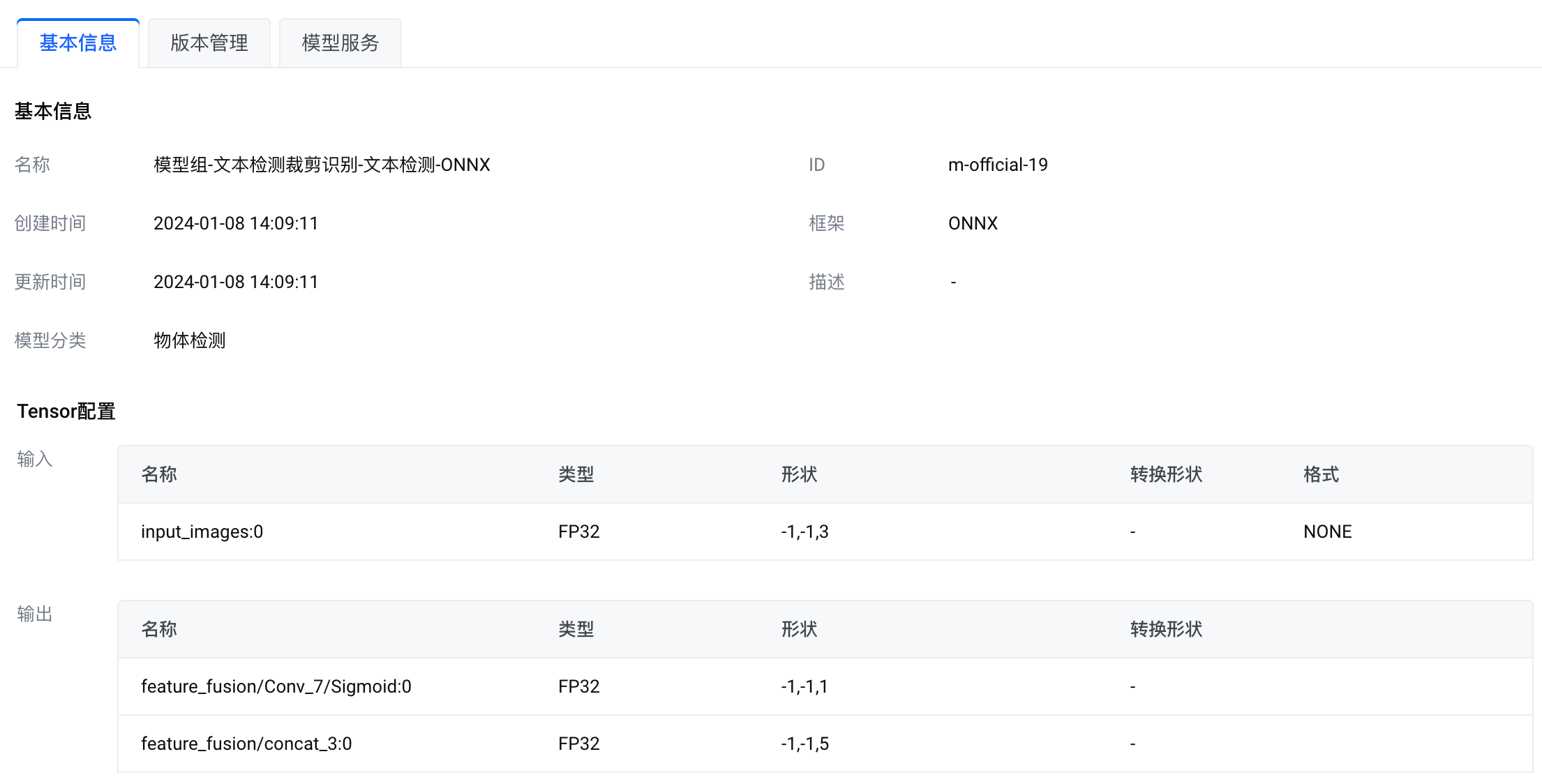
模型组-文本检测裁剪识别-文本检测-ONNX |
|
模型组-文本检测裁剪识别-组合模型 |
|
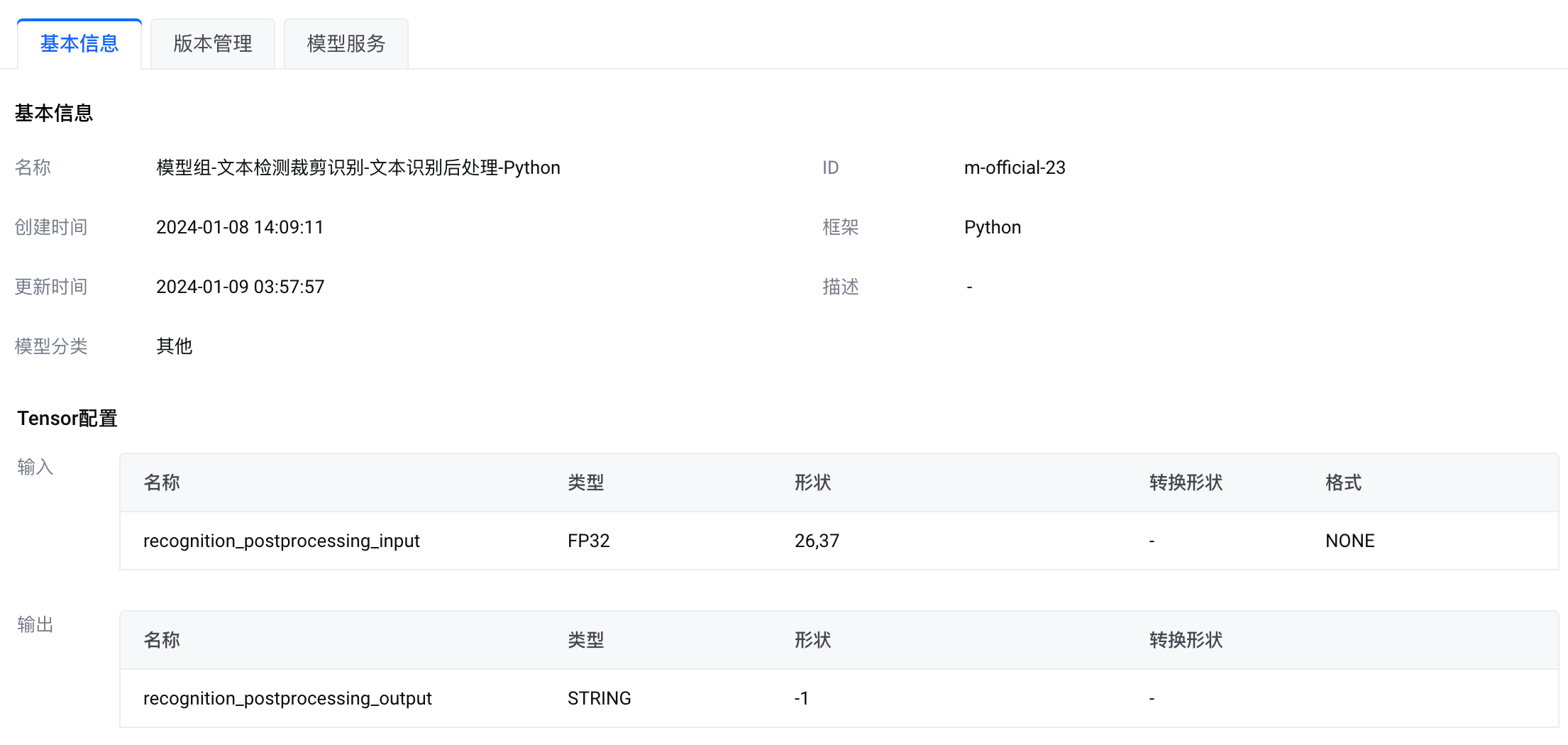
模型组-文本检测裁剪识别-文本识别后处理-Python |
|
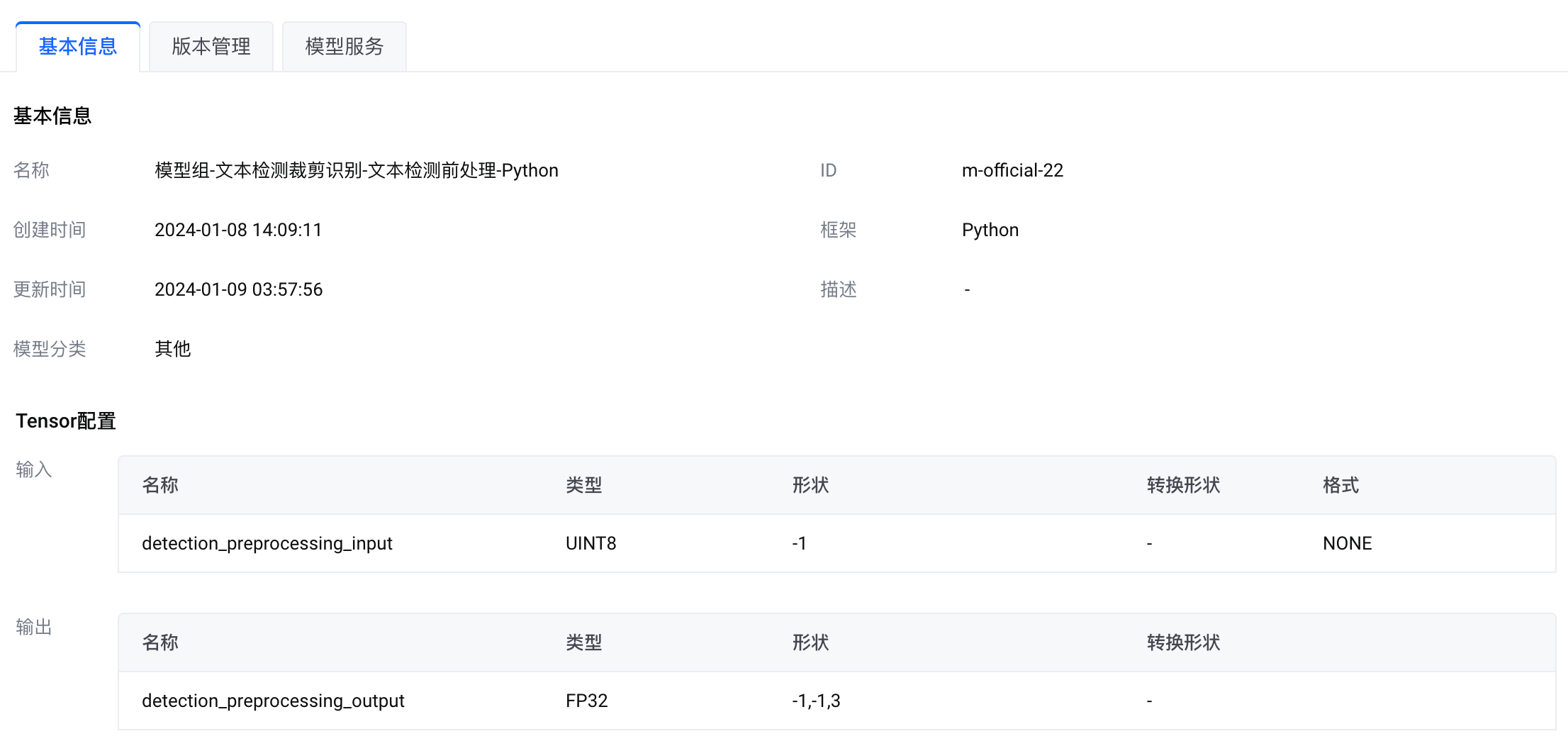
模型组-文本检测裁剪识别-文本检测前处理-Python |
|
Ensemble 模型输入
名称 | 类型 | 形状 |
|---|---|---|
input_image | UINT8 | -1 |
输入说明:
- 本模型只支持同时输入一张图像。
- 图像的长度和数量是可变的。同时,图像是以二进制的形式进行存储和处理的。
Ensemble 模型输出
名称 | 类型 | 形状 |
|---|---|---|
recognized_text | STRING | -1 |
输出说明:输出从图片中识别出的文字,以字符串数组格式返回。
Ensemble 模型版本
本模型提供一个可部署版本。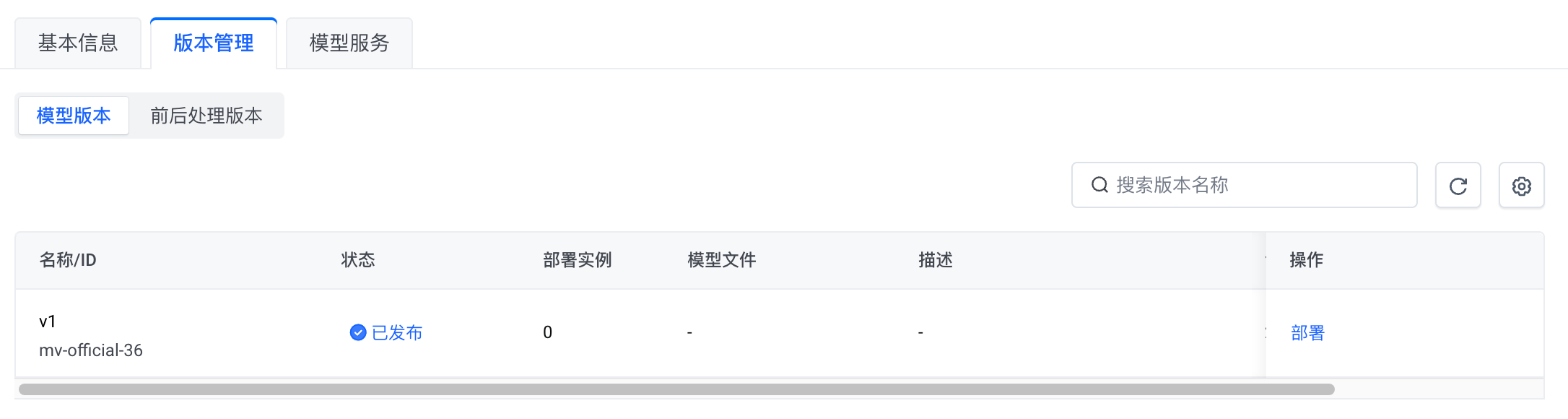
版本名称 | 最大批处理大小 | 硬件架构要求 | 说明 |
|---|---|---|---|
v1 | 取值范围:1~128。您可以根据边缘一体机的处理能力(例如,CPU、内存等)来确定最大批处理大小。边缘一体机处理能力越高(如 CPU 和内存配置较高),则可选择的最大批处理大小相对也较高。 | 无 | 该版本无需搭配前后处理版本进行使用。 |
Ensemble 模型部署
参考 部署模型服务进行模型服务的部署。在 部署模型服务 参数配置页面,修改以下配置:
说明
下表中未包含的配置项无需修改,统一使用默认值。
类型 | 配置项 | 说明 |
|---|---|---|
基本信息 | 一体机 | 选择一台一体机。 |
服务名称 | 设置一个服务名称。服务名称在一台一体机上必须保持唯一。 | |
模型信息 | 模型 | 选择 模型组-文本检测裁切识别-组合模型。 |
模型版本 | 选择 v1。 | |
服务配置 | HTTP端口 | 指定一个一体机上空闲的端口。 |
GRPC端口 | 指定一个一体机上空闲的端口。 |